

全断面隧道掘进机(tunnel boring machine, TBM)是现代化隧道施工的核心装备。其通过旋转刀盘驱动滚刀破碎岩体,实现连续高效掘进。相较于传统工法,它具有施工精度高、对环境影响小、成洞质量高等显著优势,在我国城市地铁、水利隧洞建设等重大工程中应用广泛[1]。然而,复杂地质条件下滚刀异常磨损问题严重制约着TBM掘进效能的发挥:在现有监测方法下,人工开仓检测需频繁停机且测量误差较大;传感器实时监测则因施工环境恶劣(如泥水冲刷、碎石冲击等)而设备失效率高、数据可靠性差。
近年来,人工智能和机器学习技术得到了飞速发展,特别是在深度学习、强化学习和自然语言处理等领域。深度学习通过多层神经网络使计算机能够从大量数据中自动学习复杂的特征,推动了图像识别、语音识别和自然语言处理等技术的突破。已有学者采用深度学习技术对TBM滚刀磨损进行了研究,取得了一定成果。如:丁小彬等[2]依托广州某地铁线路项目,对比了卷积神经网络(convolutional neural network,CNN)、长短期记忆网络(long short-term memory,LSTM)等深度学习方法与传统多层感知机模型在滚刀磨损预测上的效果,得出深度学习方法优于传统基于神经网络的方法的结论;Mo等[3]采用地层切片法并结合改进粒子群算法优化的LSTM模型,实现了对盾构机刀具磨损状态的实时准确预测。然而,对于TBM滚刀磨损预测而言,存在磨损标签数据不足的情况。如:在Ding等[4]的研究中,滚刀磨损数据的测量间隔为10~80个掘进循环,远低于输入参数即地质条件参数和TBM运行参数的获取频率,因此该研究在构建数据集时采用经验公式来估算磨损值;Zhang等[5]在关于滚刀磨损预测的研究中,同样由于滚刀的检测记录较少而出现了磨损数据不足的情况,该研究解决滚刀磨损标签数据不足的方法是假设滚刀在相邻磨损记录之间的径向磨损呈线性增加。这些方法在滚刀磨损标签数据不足的情况下可以起到一定的扩充数据集的作用,但在一定程度上失去了数据的真实性,丧失了实际意义。因此,需要一种新的扩充磨损标签数据集的方法,来应对磨损标签数据不足的情况。
本文提出一种基于图拉普拉斯正则化(graph Laplacian regularization,GLR)深度学习模型的滚刀磨损预测方法。采用GLR的半监督学习(semi supervised learning,SSL)方法为滚刀磨损预测模型扩充数据集,再利用深度学习模型强大的特征提取和自适应能力,对滚刀磨损进行预测,实现对滚刀磨损信息的精准掌控,为施工过程中的TBM维护和决策提供科学依据。该方法不仅能有效应对数据稀缺的问题,还能提高预测的准确性和可靠性,为提高TBM工作效率和降低维护成本提供重要支撑。
1 工程工况介绍
1.1 工程背景
本研究所属的项目为国家重点研发计划“工业软件”专项——“复杂施工环境下大型工程装备设计/制造/运维一体化平台研发与应用”项目,研究依托某高原隧道掘进工程展开。该工程为双线隧道,采用全断面硬岩TBM进行双向掘进。隧道总长度达37.9 km,研究标段施工长度为17.7 km;地处高海拔地区,最高点海拔为4 728 m,最大埋深为1 680 m。研究区段穿越的围岩以高强度的花岗岩、片麻岩为主,地质勘察数据显示,岩石单轴饱和抗压强度基本为120~180 MPa,部分区段达200 MPa以上,属于极硬岩范畴;围岩等级以Ⅱ、Ⅲ级为主,局部为Ⅳ级;岩体中石英的质量分数含量普遍高于30%,部分层位达45%以上,磨蚀性指标(如Cerchar磨蚀指数)属强磨蚀等级。这类高硬、强磨蚀性地层会对TBM滚刀造成严重磨损,是制约掘进效率、影响刀具更换周期和工程进度的关键因素。因此,对滚刀磨损状态进行精准预测与健康管理,是亟待解决的核心工程问题之一,具有重要的现实紧迫性。TBM施工现场如图1所示。
图1

1.2 滚刀磨损指标构建
滚刀安装在TBM刀盘上,在TBM掘进过程中,刀盘旋转而带动滚刀绕刀盘的中心轴线公转,同时滚刀本身会自转,对岩石产生挤压、剪切等作用,使岩石不断脱落,从而达到破岩的目的。刀盘正面如图2所示。刀盘上排列分布了66把滚刀,其中含4把双刃滚刀,总共70刃,分别编号为1, 2, …, 70。
图2
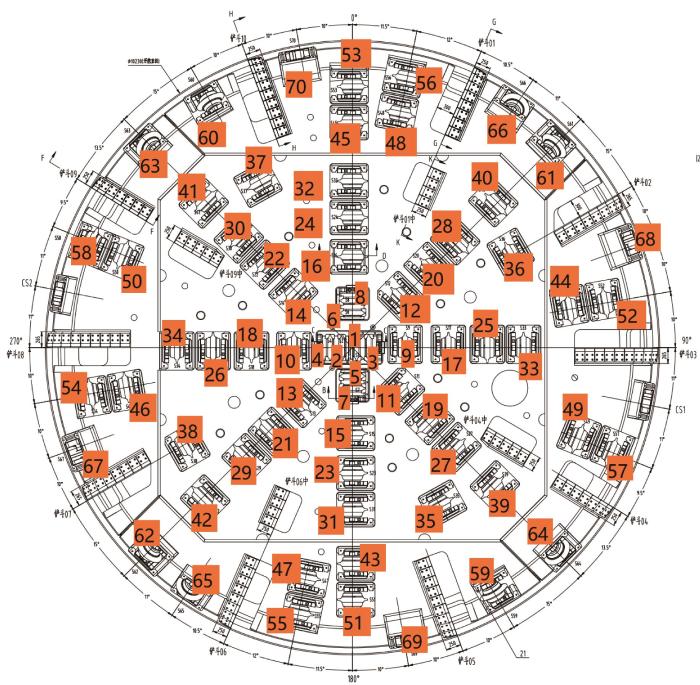
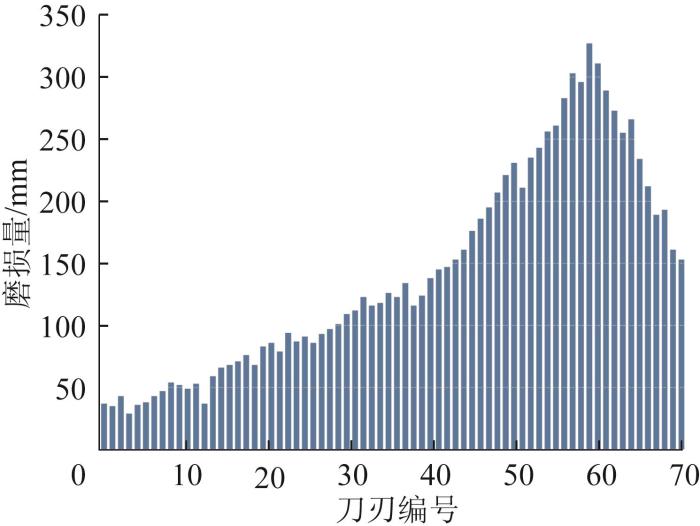
根据滚刀安装半径,滚刀安装区域可划分为中心区、正面区和边缘区,其中中心区滚刀的安装半径最小,其次为正面区,边缘区滚刀的安装半径最大。根据人工查刀记录,对2 000个掘进循环后滚刀磨损量进行统计,结果如图3所示。由图可知,滚刀磨损量先随安装半径的增大而增大,59号刀刃的磨损量最大,随后随安装半径的增大逐渐减小,这是由于滚刀磨损量受到安装半径和安装角度的共同影响。在中心区和正面区,滚刀始终垂直于掌子面,即滚刀安装角度不变,滚刀磨损量由安装半径决定,安装半径越大,滚刀在TBM掘进过程中的运动路径越长,因此磨损量也就越大;在边缘区,滚刀安装角度逐渐增大,滚刀与掌子面的夹角增大,导致滚刀与掌子面的接触面积变小,若只考虑安装角度的影响,磨损量会逐渐减小,因此当边缘区某些位置滚刀安装角度对磨损量的影响超过安装半径的影响时,随着安装半径的增大,滚刀磨损量依然呈现下降趋势。
图3
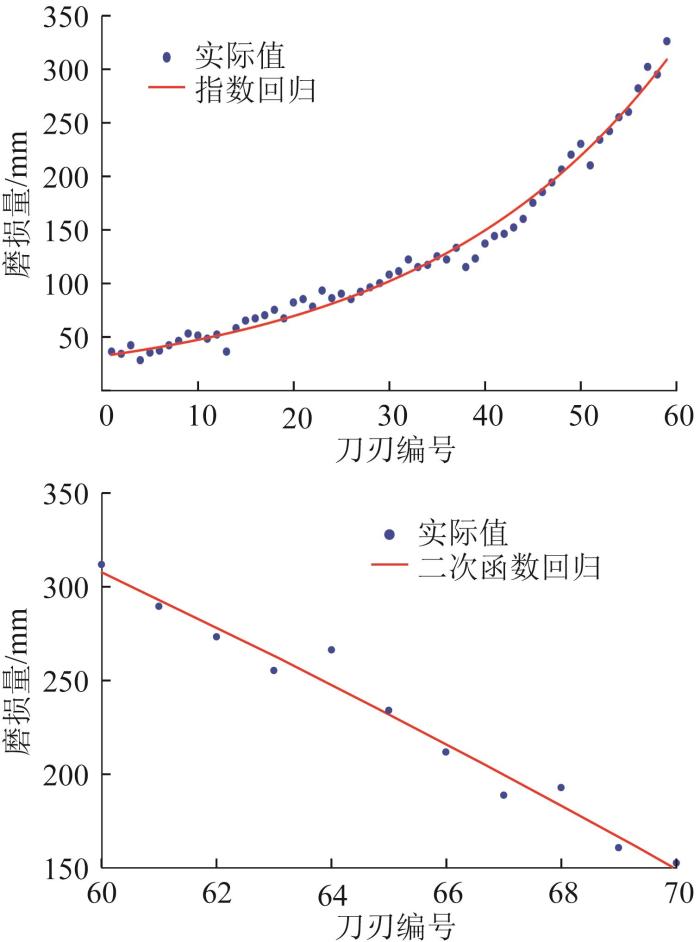
为了研究滚刀磨损量与安装半径、安装角度的关系,分别采用指数回归、多项式回归和乘幂回归等方法对滚刀磨损量进行回归分析。首先,对1~59号刀刃的磨损量进行回归分析,发现指数回归模型的拟合效果最好,决定系数R²=0.986 421,回归公式为
图4
一部分滚刀磨损信息通过工人开仓测量获取。这种方法耗时耗力,工人每开仓测量1次,TBM就得停机数小时,因此在TBM实际工作过程中应严格控制开仓测量的次数,由此导致所获取的人工测量数据十分有限。另一部分通过传感器获取。为了获取TBM运行状态下的参数信息,在TBM上加装了多种传感器,其中安装在刀盘上的电涡流传感器如图5所示,用于监测滚刀的磨损情况,获取滚刀磨损量。电涡流传感器造价昂贵,考虑到成本问题,所安装的电涡流传感器数量有限,且其在TBM掘进过程中易受到泥水冲刷和碎石冲击等,在运行一段时间后全部受损,因此收集到的数据也很有限。通过查阅TBM运行日志表,分析比较人工开仓测量数据和电涡流传感器收集的数据,最终经过计算得出一个包含TBM滚刀磨损速率标签的小样本数据集。
图5

1.3 TBM运行参数
除了获取小样本带磨损标签的数据外,还需获取在TBM掘进过程中不带磨损标签的运行参数。为了获取TBM运行参数,在其内部安装了多种传感器,如检测转速的地磁传感器、检测温度的温度传感器等,采集到的大量运行参数可为TBM运行维护和决策部署提供参考。
传感器采集的部分TBM运行参数如表1所示。
表1 部分TBM运行参数
Table 1
| 推进速度/(mm/min) | 贯入度/(mm/r) | 总推进力/kN | … | 撑靴撑紧力/kN | 地磁传感器脉冲频率/Hz |
|---|---|---|---|---|---|
| 28 | 4.5 | 23 540 | … | 26 180 | 811 |
| 24 | 3.9 | 23 650 | … | 26 180 | 824 |
| 27 | 4.4 | 23 650 | … | 26 160 | 831 |
| 26 | 4.2 | 23 540 | … | 26 140 | 870 |
| 30 | 4.9 | 23 330 | … | 26 140 | 801 |
| 30 | 4.9 | 23 650 | … | 26 000 | 822 |
| … | … | … | … | … | … |
| 28 | 4.6 | 23 760 | … | 26 000 | 807 |
| 30 | 4.9 | 23 650 | … | 25 980 | 812 |
| 34 | 5.5 | 24 300 | … | 25 940 | 823 |
2 数据预处理
2.1 掘进循环提取
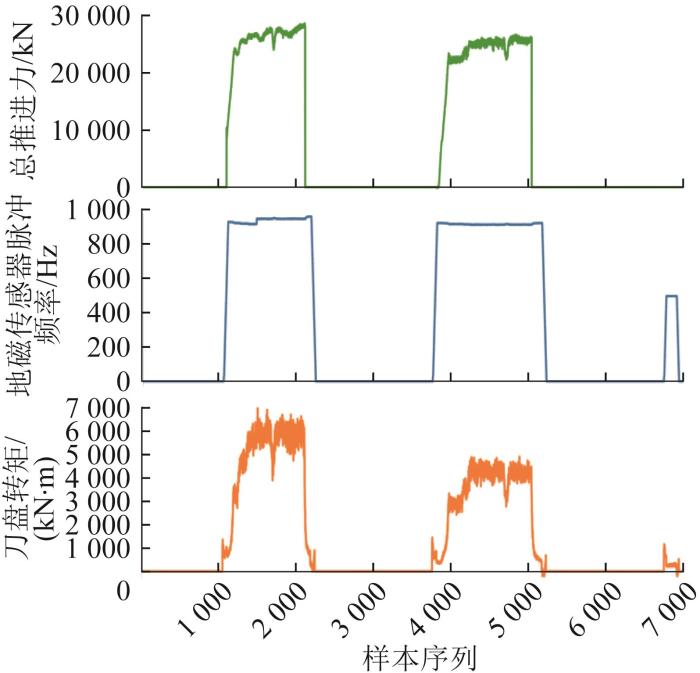
在TBM实际运行过程中,存在着掘进阶段和停机、支护等非掘进阶段。其运行循环如图6所示。
图6
在非掘进阶段,TBM的运行参数大多为0,且滚刀不会磨损。如果将这些非掘进阶段的参数导入模型,将会影响模型的预测性能,因此应该提取TBM掘进阶段的运行参数。本文采取以下措施进行提取。
推进速度、总推进力、地磁传感器脉冲频率和刀盘转矩等4个参数是TBM掘进阶段的主要参数,能从根本上反映TBM的掘进状态。当这4个参数中的任意一个为0时,视为TBM处于非掘进阶段,并对该阶段的数据进行剔除。因此,以这4个参数为基准,剔除这4个参数中任意一个为0的部分,剩下的即为TBM掘进阶段的数据。
TBM掘进循环如图7所示。由图可知,在TBM掘进阶段各参数并不是平稳不变的。每个掘进循环可分为3个阶段:空推段、上升段和稳定段。其中空推段的形成是因为经过每个掘进阶段后,驾驶员会将TBM刀盘退离掌子面一段距离,以方便进行TBM状况检查、故障检修等。因此,当TBM再次运行时,刀盘会先产生空推,运行一段距离后再与掌子面接触。由于TBM再次运行时刀盘由静止不动到在扭矩的驱动下加速到一个稳定的转速后再与掌子面接触,空推段的TBM刀盘转矩先等价于刀盘的启动转矩与摩擦阻力矩之和,当地磁传感器脉冲频率达到一定值时,刀盘转矩则只等价于摩擦阻力矩,因此刀盘转矩在空推段呈现先急剧增大后减小直至短暂稳定的趋势。在上升段,刀盘开始与掌子面接触,驾驶员调节刀盘转矩使其持续增大,以达到破岩的目的。在稳定段,驾驶员控制刀盘转矩,使其不再增大,而是稳定在一定范围内呈小幅波动,TBM进入稳定工作状态。
图7
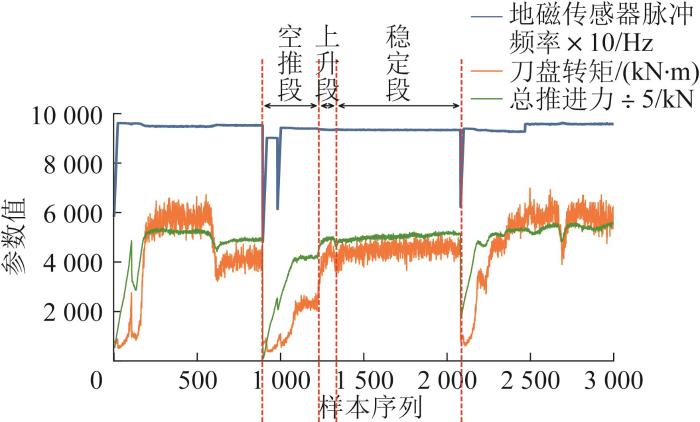
在空推段,滚刀未与掌子面接触,并未造成磨损,所以该段的数据也应该剔除。上文已经分析,在TBM掘进循环中刀盘转矩具有非常明显的变化趋势,因此可以基于刀盘转矩对空推段的数据进行剔除。在空推段,刀盘转矩先急剧增大后减小直到短暂稳定,将这个短暂稳定段定义为Short-term;在上升段和稳定段,刀盘转矩持续增大直到长时间稳定,将这个长时间稳定段定义为Long-term。可以通过对Short-term和Long-term的定位来确定TBM掘进循环的各工作段,具体方法如下。
1)对刀盘转矩进行分析与处理。用Pandas中的rolling方法结合std( )函数创建滑动窗口并计算标准差,当窗口标准差连续低于设定阈值时,判定TBM进入稳定状态,同时要求稳定状态的持续时间至少覆盖2个连续窗口,以避免瞬时波动引起的误判。通过这种方法可以将TBM各个掘进循环的稳定段识别出来。
2)将各个掘进循环的稳定段进行识别后提取,计算其刀盘转矩均值和持续时间。由于刀盘转矩在空推段短暂稳定后会继续增大直到长时间稳定,因此Short-term的平均刀盘转矩低于Long-term的平均刀盘转矩,且在Short-term的持续时间短于在Long-term的持续时间。将刀盘转矩平均值偏小且持续时长偏短的稳定段标记为Short-term,刀盘转矩平均值偏大且持续时长偏长的稳定段标记为Long-term,最后定位Short-term的结束位置,作为空推段的结束位置,进而将空推段的数据予以剔除。
2.2 异常数据剔除和滤波降噪处理
图8
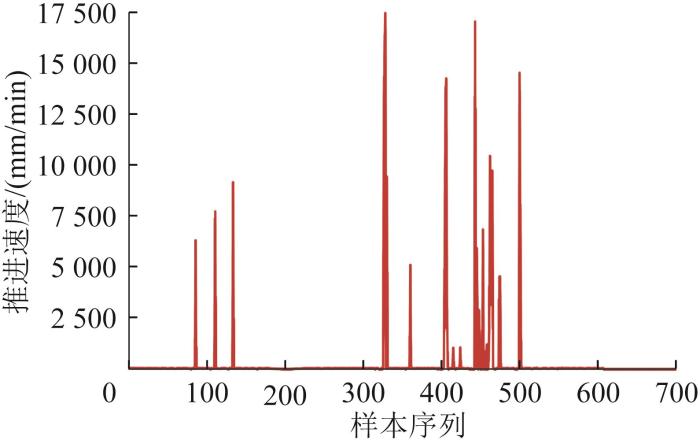
本研究用四分位法对原始数据中的异常数据进行处理。对提取后的时序数据进行多个滑窗的划分,在每个滑窗内计算四分位数、四分位距和异常值上下限,然后对异常突变数据进行剔除。异常数据处理后部分参数的箱形图如图9所示。
图9
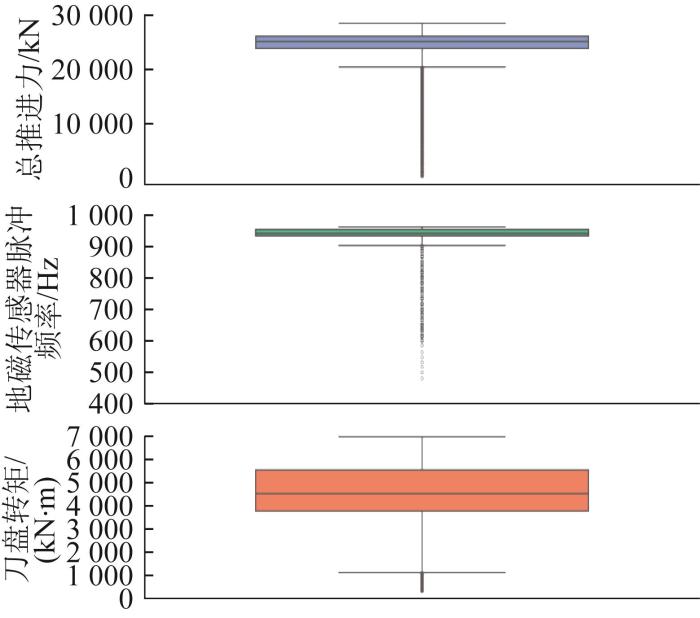
图9
异常数据处理后部分参数箱形图
Fig.9
Box plots of partial parameters after handling abnormal data
TBM在掘进过程中会受到振动、地质条件变化、设备故障等因素的干扰,导致采集的运行数据除了异常数据以外,还可能存在噪声。噪声会对模型的性能产生严重影响,因此需对运行数据进行滤波处理,以有效去除噪声,保证数据的可靠性,同时能够平滑数据,便于分析。本研究采用SG(Savitzky-Goloy)滤波方式对数据进行降噪处理。滤波处理前后部分参数的对比如图10所示。
图10
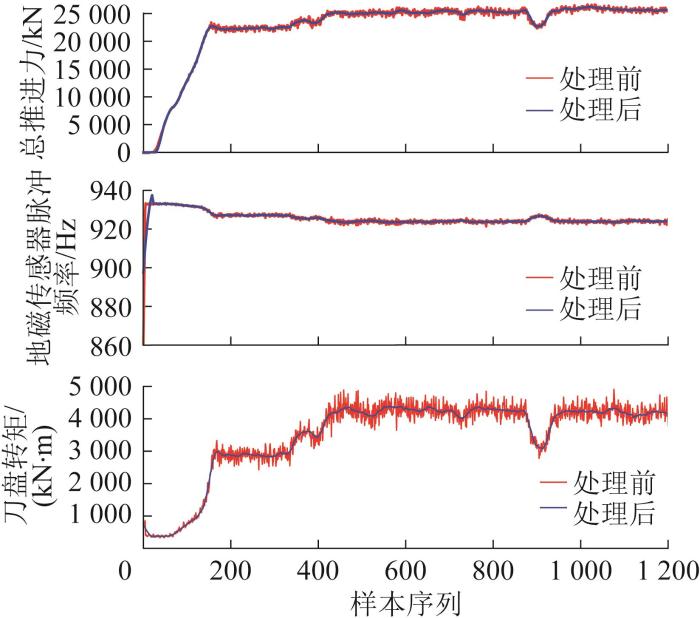
图10
滤波处理前后部分参数对比
Fig.10
Comparison of partial parameters before and after filtering processing
2.3 模型参数选择
影响TBM掘进过程的因素较多,因此模型输入参数来源于多个维度,包括地质条件参数和TBM运行参数等[9]。在本研究中,地质条件参数主要指围岩等级。围岩等级反映了围岩的强度和稳定性等,分为Ⅰ级到Ⅵ级,共6个等级,从Ⅵ级到Ⅰ级围岩的强度逐渐提高,意味着TBM掘进难度逐渐增大。
在实际施工中,地质条件信息的实时获取存在较大困难。采样设备难以实时捕捉复杂多变的地质条件,信息更新延迟,同时高精度地质勘察的成本高昂,使得可用于模型开发的高质量、高分辨率的地质条件参数(尤其是关键的岩石磨蚀性参数)数据极为有限。而大量研究表明,TBM运行参数的变化在一定程度上可以反映地质条件的变化,即TBM运行参数中包含了一定的地质条件信息。如:Yagiz[10]证实了岩体特性(如结构面间距、单轴抗压强度、结构面产状、岩石脆性等)是影响贯入度的关键因素;Liu等[11]整合了刀盘转速、推力、转矩、功率和推进速率等TBM运行参数,成功构建了关键岩体参数的预测模型。TBM运行参数与地质条件之间具有密不可分的关系,因此本文选取部分TBM运行参数作为模型输入,同时为了弥补地质条件信息的缺失,间接反映岩石破碎难度和磨蚀性特征,特别引入以下2个关键复合掘进指数作为补充输入参数[12-13]。
1)现场贯入指数IFP。定义为总推进力F与推进速度vp或贯入度P的比值,即IFP=F/vp或IFP=F/P。IFP是表征岩石破碎难度的经典指标,高IFP值通常意味着岩石很坚硬或破碎很困难。
2)扭矩贯入指数ITP。定义为刀盘扭矩T与推进速度vp或贯入度P的比值,即ITP=T/vp或ITP=T/P。ITP与岩石的磨蚀性、结构面发育程度等特性密切相关,高ITP值通常表征高磨蚀性或不良地质条件。
将IFP和ITP纳入模型输入参数集,可以使模型直接利用运行参数中蕴含的与岩石强度、磨蚀性等关键地质特性高度相关的信息,从而在无法直接获取原始地质条件参数(尤其是磨蚀性参数)的条件下,显著增强对地质条件变化的感知和适应能力,有效弥补因地质条件参数缺失带来的潜在性能损失。
基于以上分析,本研究选择的预测模型参数如表2所示。
表2 预测模型参数
Table 2
| 序号 | 参数 | 单位 | 类型 |
|---|---|---|---|
| 1 | 地磁传感器脉冲频率 | Hz | 输入参数 |
| 2 | 刀盘转矩 | kN·m | 输入参数 |
| 3 | 总推进力 | kN | 输入参数 |
| 4 | 推进速度 | mm/min | 输入参数 |
| 5 | 贯入度 | mm/r | 输入参数 |
| 6 | IFP | kN/(mm/r) | 输入参数 |
| 7 | ITP | kN·m/(mm/r) | 输入参数 |
| 8 | 磨损速率 | mm/h | 输出参数 |
本研究的有标签数据为包含磨损速率这一标签的数据。如前文所述,由于受到泥水冲刷和碎岩冲击等,监测磨损情况的电涡流传感器在运行一段时间后全部损坏,实际收集到的磨损信息极少,加上通过查阅TBM运行日志表所记录的数据,得到的磨损标签数据仅为66条。而无标签数据为不包含磨损速率这一标签的数据,即仅包含地磁传感器脉冲频率、刀盘转矩、总推进力、推进速度、贯入度、IFP和ITP,共计10 283条。
3 基于GLR深度学习模型的TBM滚刀磨损预测模型
含磨损标签的数据集为极端小样本数据集,而无标签数据样本高达上万条。对于含有少量有标签数据和海量无标签数据的数据结构,通常采用SSL方法来处理,而GLR是SSL的一种重要方法。基于GLR理论,本文创新性地提出了一种融合GLR与深度学习的滚刀磨损预测模型。通过构建数据流形结构,有效整合少量有标签数据与海量无标签数据的协同信息,突破了极端小样本条件下模型训练的数据瓶颈。具体而言,模型采用两阶段设计:第1阶段利用GLR生成高置信度伪标签,显著扩充训练样本;第2阶段将伪标签数据与原始标签数据融合,来训练LSTM、CNN和DNN(deep neural network,深度神经网络)网络,实现端到端的预测。这一两阶段架构既充分挖掘了无标签数据的流形结构信息,又发挥了深度学习模型的特征提取优势,为小样本场景下滚刀磨损预测提供了新型解决方案。
3.1 GLR简介
SSL是机器学习的一种重要方法,它介于监督学习(supervised learning,SL)和无监督学习(unsupervised learning,UL)之间,不同于SL通过有标签数据进行训练和UL在无标签数据集上进行学习,而通常用少量有标签数据和大量无标签数据进行训练。相较于SL,SSL可以减少对有标签数据的需求,在一些有标签数据获取困难或获取较为昂贵的场景中可以减少开支,节约成本。相较于UL,SSL能充分捕捉大量无标签数据的信息,提高模型的泛化能力和鲁棒性。SSL方法主要分为基于生成模型的方法、基于伪标签的方法和基于图结构的方法等。基于生成模型的方法又分为半监督变分自动编码器方法[14-15]和半监督生成对抗网络方法[16-17]。基于伪标签的方法主要包含自训练[18]和多视角训练[19]这2种常见的策略,用于利用无标签数据增强模型的学习能力。基于图结构的代表性方法涵盖标签传播算法[20-21]、图神经网络[22-23]和流形正则化方法[24]。SSL以其显著的优点和较广的应用场景成为近年来的研究热点。然而,目前对于SSL的研究主要集中在分类问题上,如在图像分类和自然语言处理等领域,对于像TBM滚刀磨损速率预测这类回归问题,研究较少。基于此,本文提出了基于GLR深度学习模型的滚刀磨损预测方法。
GLR的理论框架由Belkin等[25]于2006年首次系统提出。该方法基于流形假设(即高维数据通常分布在低维流形结构上,且邻近样本在流形上具有相似的特征或标签),引入拉普拉斯矩阵作为正则化项,能够有效利用无标签数据的几何分布信息,约束模型在流形空间中的平稳性,从而提升小样本场景下模型的泛化性能。
GLR算法通过显式构建数据几何结构,将流形学习与监督学习相结合。其核心是通过高斯核函数度量样本间的局部相似性,构造邻接矩阵,然后基于邻接矩阵进一步构造拉普拉斯矩阵,以表征数据流形的拓扑结构。其公式如下:
式中: W 为邻接矩阵; xi 和 xj 分别为第i和j个样本的特征向量;
3.2 GLR深度学习模型原理
GLR深度学习模型的结构如图11所示。模型分为两部分,一部分为伪标签数据集生成部分,另一部分为参数预测部分。伪标签数据集生成部分是基于无标签数据和小样本有标签数据,利用GLR方法建立数据之间的相似性关系,使用k近邻(k-nearest neighbor,k-NN)算法建立稀疏邻接矩阵,构建k-NN图结构,然后计算正则化拉普拉斯矩阵,建立正则化模型,最后用训练好的正则化模型预测磨损标签,将生成的磨损标签与无标签数据集结合,即可得到伪标签数据集。参数预测部分是将得到的伪标签数据集与有标签数据集融合,完成训练数据的数据集扩充,然后将经过扩充的含磨损标签的大量数据样本输入深度学习模型,完成深度学习模型的训练。
图11
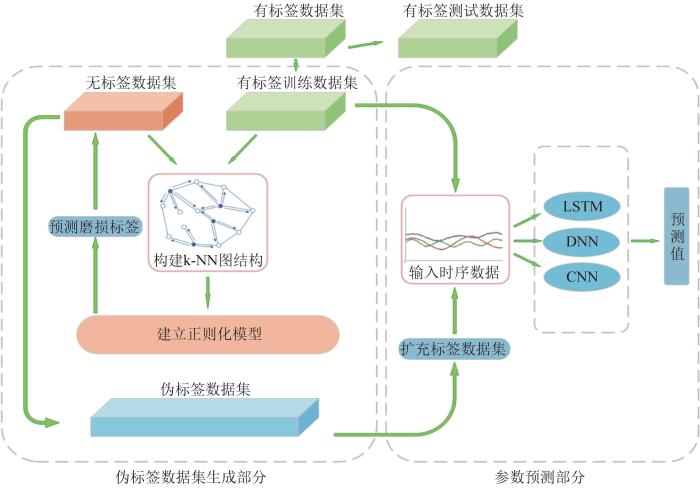
GLR深度学习模型对于TBM滚刀磨损预测的步骤如下:
1)将小样本的有标签数据集作切片分割处理,各由50%的数据构建有标签训练数据集和有标签测试数据集。
2)将有标签训练数据集与无标签数据集合并,然后统一进行标准化处理,并初始化GLR模型的参数。
3)基于有标签训练数据和无标签数据构建k-NN图结构,计算正则化拉普拉斯矩阵,并建立正则化模型。用建立好的模型预测无标签数据的磨损标签,并为无标签数据贴上磨损速率标签,从而得到伪标签数据集。将伪标签数据集与有标签训练数据集结合,即可得到大量含磨损速率标签的数据,并将其作为深度学习模型的输入数据。
4)将所得到的输入数据输入不同的深度学习模型,计算损失、反向传播并更新参数,即可完成不同深度学习模型的训练,再将从有标签数据切片分割出来的有标签测试数据输入不同的深度学习模型,比较模型的3个性能指标——均方根误差ERMS、平均绝对误差EMA和决定系数R²,分析模型的预测性能。
3.3 GLR深度学习模型的构建及训练
对GLR-LSTM、GLR-DNN和GLR-CNN等3种深度学习模型进行构建及训练。
对GLR-LSTM模型的架构进行设定:输入维度为7,输出维度为1,模型层数为1,隐藏层神经元个数为32,Dropout率为0.3,全连接层数为1。对GLR-DNN模型的架构进行设定:输入维度为7,输出维度为1,模型层数为2,神经元个数分别为64和32,激活函数选用Tanh,Dropout率为0.4,输出层采用缺陷设计(32→16→1)。对GLR-CNN模型的架构进行设定:输入维度为7(重构为通道维度),输出维度为1,一维卷积层数为2,卷积核大小分别为3和2,通道个数分别为16和32,全连接层数为2(32→16→1),Dropout率为0.3。所有模型的训练均采用标准化数据并注入双重高斯噪声(噪声因子为0.25+0.1),训练迭代次数统一设定为50,学习率设定为0.000 5,优化器选用AdamW并添加权重衰减1e-3,采用学习率调度策略(Plateau检测,耐心值为5),梯度裁剪阈值分别设定为1.0(GLR-LSTM和GLR-CNN)和0.5(GLR-DNN),批量大小设定为64。
3.4 GLR深度学习模型预测效果对比
图12
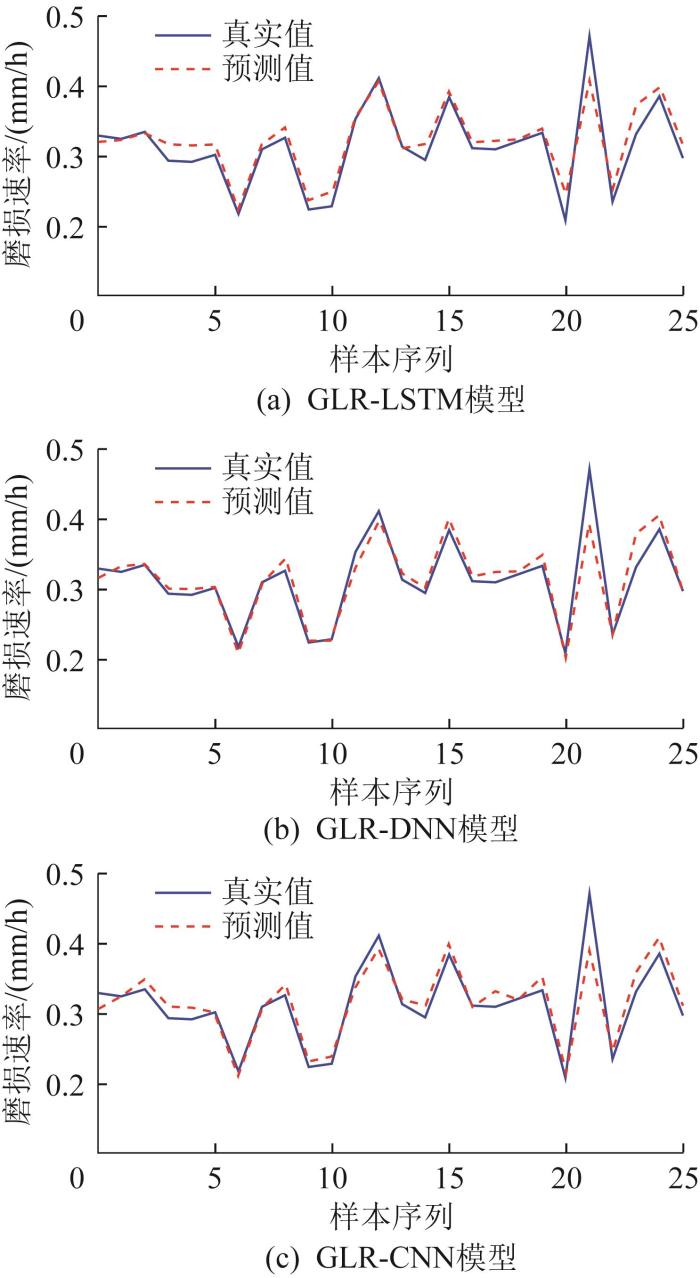
图12
GLR深度学习模型预测值与真实值对比
Fig.12
Comparison of predicted values obtained by GLR deep learning models and actual values
表3 GLR深度学习模型预测性能
Table 3
| 模型 | ERMS | EMA | R² |
|---|---|---|---|
| GLR-LSTM | 0.000 76 | 0.018 42 | 0.890 09 |
| GLR-DNN | 0.001 07 | 0.019 29 | 0.844 93 |
| GLR-CNN | 0.000 84 | 0.018 49 | 0.878 58 |
由表3可知,各模型预测误差均较低且在合理的范围内,模型整体性能表现稳定。具体来看,GLR-LSTM模型表现出最优的综合预测性能,ERMS=0.000 76,为最小,R²=0.890 09,为最大,表明该模型预测值与真实值之间的偏差最小且解释力最强。虽然GLR-DNN模型的EMA=0.019 29,略大于GLR-LSTM模型,但其ERMS显著大于GLR-LSTM,R²显著小于GLR-LSTM。GLR-CNN模型的性能介于GLR-DNN与GLR-LSTM之间。根据模型预测性能核心评价指标值可知,GLR-LSTM模型在TBM滚刀磨损预测中具有最高的精度,其输出结果与真实数据具有最佳的一致性。
GLR-LSTM模型具有最优异的性能,主要归因于其架构特性与正则化策略的有效结合,具体为以下几点。首先,LSTM具有一定的结构优势。LSTM本身擅长捕捉时间序列或序列数据中的长期依赖关系和动态模式,这对于具有时序或顺序关联性图节点的特征预测至关重要,其内置的门控机制能有效学习并记忆关键的历史信息。其次,LSTM固有的序列建模能力与GLR的结合产生了最佳的协同效应,GLR显式地将图的结构信息(邻接关系)引入模型训练过程,使相邻节点的预测结果趋于平稳,这有效利用了数据内在的图结构先验知识,增强了模型对图拓扑结构的理解能力。这种图结构信息的引入与LSTM相得益彰,使得LSTM与GLR结合后模型具有更大的R²值和更小的ERMS值。相比之下,DNN尽管结构灵活,但在处理具有强结构关系(如时序依赖、图邻接)的数据时,缺乏对这类内在模式针对性的建模能力,性能相对受限。CNN虽然对提取局部空间特征高效,但其平移不变性的假设在处理非欧几里得结构的图数据或复杂时序模式时不如LSTM直接有效。
3.5 GLR深度学习模型与小样本机器学习模型的对比
处理小样本数据时,除了上文提到的SSL方法外,部分研究还采用了机器学习方法,如线性回归法、支持向量机等。本研究采用以下3种小样本机器学习方法——岭回归(ridge regression,RR)、支持向量机回归(support vector regression,SVR)和梯度提升回归树(gradient boosting regression tree,GBRT),对TBM滚刀磨损进行预测。
对该3种传统机器学习模型进行系统性的架构设计与参数配置。对RR模型进行设定:采用L2正则化并通过网格搜索优化正则化系数α(搜索范围为10⁻³~10³,共20个对数点),交叉验证折数为5。对SVR模型进行设定:采用径向基核函数,通过三维网格搜索优化惩罚系数C(0.1~1 000,共5个数量级)、核系数gamma(0.001~10,共5个数量级)和不敏感带epsilon(0.01~0.3,共5个值)。对GBRT模型进行设定:基学习器个数为100,学习率为0.1,最大深度为3,随机种子个数为42。所有模型的数据均进行训练集和测试集划分,80%为训练集,20%为测试集,随机种子个数为42。RR和SVR采用Z-score标准化数据,GBRT直接使用原始特征。模型预测性能评估采用测试集的ERMS、EMA、R²指标,其性能如表4所示。3种模型与GLR深度学习模型预测性能的对比如图13所示。
表 4 机器学习模型预测性能
Table 4
| 模型 | ERMS | EMA | R² |
|---|---|---|---|
| RR | 0.007 936 | 0.079 145 | 0.383 7 |
| SVR | 0.008 125 | 0.092 167 | 0.328 3 |
| GBRT | 0.008 053 | 0.081 352 | 0.335 7 |
图13
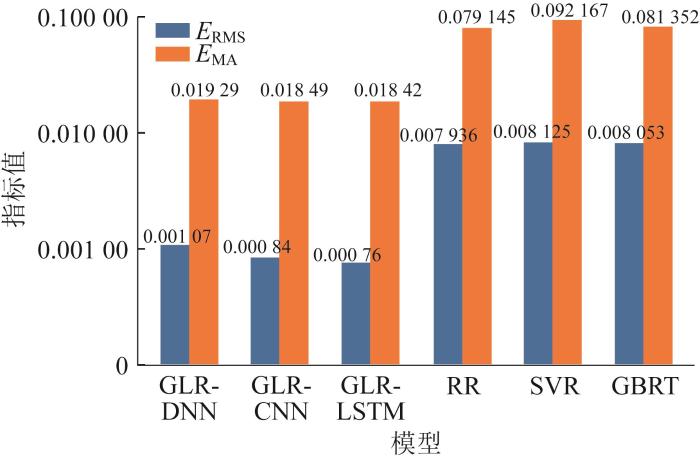
图13
机器学习模型与GLR深度学习模型预测性能对比
Fig.13
Comparison of prediction performances of machine learning models and GLR deep learning models
由表4可知,传统小样本机器学习方法在极端小样本场景下存在显著局限性,RR、SVR和GBRT在测试集上的表现较差,R²=0.32~0.39,而ERMS≈0.008,显著大于GLR深度学习模型。原因可能在于滚刀磨损速率与多源参数(地质条件参数、TBM运行参数等)之间特征-标签映射的复杂性,传统浅层模型难以捕捉这种复杂映射,并且66个样本难以支撑传统模型参数的优化,存在小样本过拟合风险。同时,传统方法仅使用66条标签数据,忽略了上万条无标签数据蕴含的流形结构信息。相比之下,GLR深度学习模型以其对流形结构信息充分利用、图结构与深度学习框架有效结合的特点,在小样本场景中展现显著优势。
4 总 结
本文针对TBM滚刀磨损人工检测效率低、传感器监测成本高且可靠性差的问题,创新性地提出了基于GLR深度学习模型的预测方法。该方法融合SSL与深度神经网络,有效解决了滚刀磨损标签数据稀缺的难题,实现了高原隧道掘进工程中TBM滚刀磨损速率的精准预测,为替代人工开仓检测、提高掘进效率和降低维护成本提供了技术支撑。本研究主要成果如下:
1)构建了数据高效预处理体系。 基于某高原隧道掘进工程的TBM运行数据,提出了掘进循环动态提取法:以关键运行参数为依据,精准剔除非掘进段数据;通过刀盘转矩短时/长时稳定特征识别,剔除无磨损空推段的数据;采用四分位法和SG滤波技术提升数据质量。
2)创新设计了GLR深度学习模型。针对极端小样本场景,将GLR引入TBM领域:构建了k-NN图来刻画数据流形结构,用拉普拉斯矩阵约束相邻样本的预测平稳性并生成伪标签扩充训练集;开发了GLR-LSTM、GLR-DNN、GLR-CNN等3种正则化深度学习模型,其中GLR-LSTM模型以ERMS=0.000 76,R²=0.890 09的显著优势获得了最优解。
3)发展了小样本学习方法论。对比实验表明:传统机器学习模型在极端小样本场景中存在局限性,而GLR框架通过利用流形结构和生成伪标签,实现了预测精度数量级的提升;LSTM的时序建模能力与GLR的协同效应是模型性能跃迁的关键。
本研究的核心创新在于将图结构先验知识与LSTM时序建模能力深度耦合,为小样本工况下机械装备状态的预测开辟了新路径。
参考文献
TBM掘进技术发展及有关工程地质问题分析和对策
[J].
Development of TBM excavation technology and analysis and countermeasures of related engineering geological problems
[J].
基于深度学习的滚刀磨损预测模型对比
[J].
Comparison of roll blade wear prediction models based on deep learning
[J].
TBM disc cutter wear prediction using stratal slicing and IPSO-LSTM in mixed weathered granite stratum
[J].
A new approach for developing EPB-TBM disc cutter wear prediction equations in granite stratum using backpropagation neural network
[J].
A new index for cutter life evaluation and ensemble model for prediction of cutter wear
[J].
A wear rule and cutter life prediction model of a 20-in. TBM cutter for granite: a case study of a water conveyance tunnel in China
[J].
基于多个隧道掘进机工程数据回归分析的滚刀磨损评价方法
[J].
Evaluation method for rolling cutter wear based on regression analysis of multiple tunnel boring machine engineering data
[J].
A field parameters-based method for real-time wear estimation of disc cutter on TBM cutterhead
[J].
TBM施工现状分析
[J].
Analysis of TBM construction status
[J].
Utilizing rock mass properties for predicting TBM performance in hard rock condition
[J].
Improved support vector regression models for predicting rock mass parameters using tunnel boring machine driving data
[J].
高磨蚀性硬岩地段敞开式TBM掘进参数优化和适应性研究
[J].
Optimization and adaptability study of open TBM excavation parameters in highly abrasive hard rock areas
[J].
TBM cutter wear under high-strength surrounding rock conditions: a case study from the second phase of the northern Xinjiang water supply project
[J].
Semi-supervised learning with deep generative models
[EB/OL].(
Disentangled variational auto-encoder for semi-supervised learning
[J].
Improved techniques for training GANs
[EB/OL]. (
Semi-supervised learning based on generative adversarial network: a comparison between good GAN and bad GAN approach
[EB/OL].(
Pseudo-labeling and confirmation bias in deep semi-supervised learning
[EB/OL].(
Combining labeled and unlabeled data with co-training
[EB/OL]. [
Learning model order from labeled and unlabeled data for partially supervised classification, with application to word sense disambiguation
[J].
Two-stage nonparametric kernel leaning: from label propagation to kernel propagation
[J].
The graph neural network model
[J].
Invariance-preserving localized activation functions for graph neural networks
[J].
Semi-supervised broad learning system based on manifold regularization and broad network
[J].
manifold regularization: a geometric framework for learning from labeled and unlabeled examples
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}