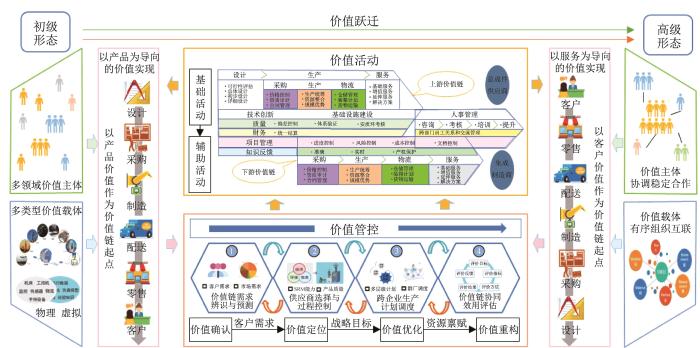
目前,制造业正面临从技术驱动到服务驱动,再到价值驱动的升级转变。将价值链协同与产品全生命周期融合,成为“工业5.0”时代复杂产品设计、制造和运维的重点。虽然复杂产品制造企业尝试利用数字化、自动化和网络化的先进技术打破产业上下游的业务、资源和信息孤岛,但受到客户需求个性化、市场环境动态化和生产系统集成化发展的影响,仍缺乏有效的产品全生命周期价值链协同设计方法,面临着生产管控效率低、协调互动困难、综合效能差等巨大挑战。复杂产品制造企业价值链演进升级的基本路径如图1 所示。通过对企业生产运营的基础活动(如设计、生产、服务等)和辅助活动(如技术创新、基础设施建设等)的系统性价值分析,挖掘产品全生命周期价值链协同设计的原理与演化及决策机制,实现复杂产品制造企业价值链从“产品价值”到“客户价值”的形式跃迁。
图1
图1
复杂产品制造企业价值链演进升级的基本路径
Fig.1
Basic path of value chain evolution and upgrading for complex product manufacturing enterprise
随着大数据技术的迅速发展,复杂产品的订单数据资源得以有效保留。这些数据资源的背后蕴含了产品价值链上多主体的市场营销信息,而大多数企业往往无法高效率、低成本地运用销售数据来辅助商业决策。如何利用这些销售数据指导企业的生产决策,仍是企业面临的重要课题。通常来讲,复杂产品的销量与天气、交通运输量等相似,是一个时间序列的预测问题[1 ] 。
时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法。传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等。然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高。传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果。但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测。
深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高。循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势。RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] 。基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] 。长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题。LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] 。门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门。GRU比LSTM网络的参数少,大大降低了复杂度。2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模。
尽管针对长时序列预测已经有了很多研究,但是针对复杂产品的长时段销量预测仍存在以下问题:1)在对原始数据的处理中,未考虑复杂产品高周转率和短保质期所带来的高订单频率的问题;2)传统的模型更多考虑了订单数据的时序和销量对销售周期的影响,而忽略了订单频率中蕴含的细节信息。为了解决以上问题,本文从长时序列预测的视角,运用深度学习理论,提出了一种基于订单时序和订单频率的改进注意力机制方法,并结合Transformer模型设计了时序-频率分解模型。
1 基于频率分段的时序预测模型的构建
Transformer模型基于编码器-解码器结构,其特点是能够有效地捕捉长期依赖关系,并利用多头自注意力机制挖掘序列数据的内在关联性[15 ] 。相比于LSTM等序列模型,Transformer模型可以一次性输入时间序列并进行并行计算,从而大大缩短计算时间,并且能够对长期和短期时序特征进行建模。
复杂产品制造企业的订单数据具有特殊性,其高周转率和短保质期带来了较高的订单频率,而Transfomer模型只考虑了订单数据的时序和销量对销售周期的影响,忽略了订单频率中蕴含的细节信息。针对这一问题,作者采用基于门控卷积的频率分段序列提取方法并改进了原始的Transformer输入编码,提出了基于改进编码的时序-频率多头自注意力(seq-fre multi-head attention)结构,用于序列间依赖关系的建模,并将改进的模型命名为SFTransformer模型。
1.1 时序-频率序列提取与输入编码
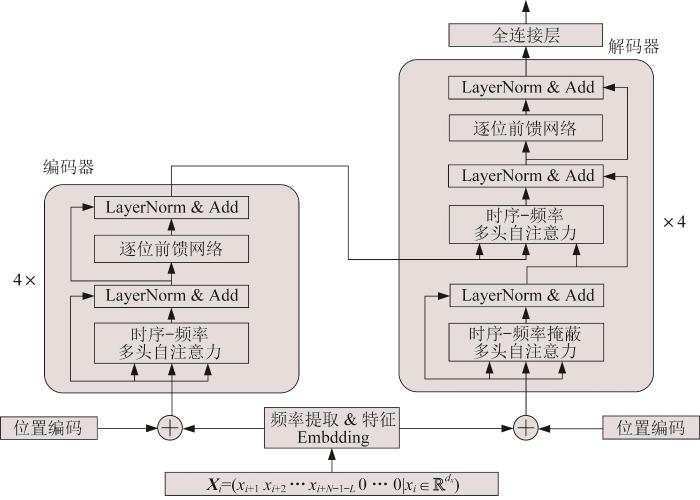
SFTransformer模型包含4层编码器-解码器架构,如图2 所示。编码器由4个相同的层叠加而成,每层都有2个子层,第1个子层是时序-频率多头自注意力模块,第2个子层是基于位置的前馈网络(position-wise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。解码器同样包含4个相同的层,每层包含1个带掩蔽操作的时序-频率多头自注意力模块,经过层归一化(LayerNorm)和残差连接(Add)处理后进入一个逐位前馈网络,随后再次经过LayerNorm和Add处理,获得该层的输出并设为下一层的输入,最终经由全连接层输出最终结果。
图2
图2
SFTransformer 模型结构
Fig.2
Structure of SFTransformer model
在上述过程中,将时序数据融合并输入SFTransformer模型,建立更大范围的位置相关性。通过离散频率编码使模型在自注意力的计算过程中能够访问不确定距离的上下文关系。向量长度可学习,因此在自注意力计算过程中对输入矩阵进行逐层折叠的同时,能够保持上下文关系的信息不丢失,以此可以得到更加准确的预测效果。
本文提出的复杂产品销量预测问题定义为:设滑动窗口定长为N ;预测步长为L ;模型输入的第i 个序列为连续时间序列 X i X i = ( x i + 1 x i + 2 … x i + N - 1 - L 0 … 0 | x i ∈ R d x ) Y i Y i = ( y i + 1 y i + 2 … y i + N - 1 | y i ∈ R d y ) d x d y R
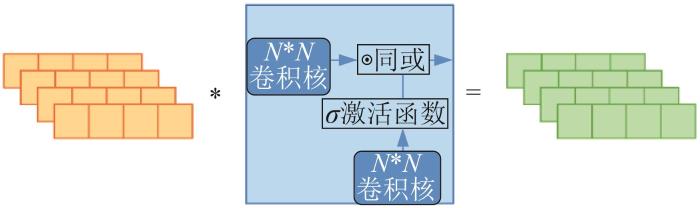
复杂产品的高周转率和短保质期带来了较高的订单频率,而传统模型更多考虑的是订单数据的时序和销量对销售周期的影响,忽略了订单频率中蕴含的细节信息。为了提取数据集中的频率信息,采取一维门控卷积操作来提取频率序列数据。一维门控卷积操作一般运用在序列数据上,不同大小的卷积操作代表着序列对不同频率的依赖[16 ] 。
为了获取不同分段的销量和频率的有效信息,SFTransformer模型先将输入的自变量X i d m o d e l d m o d e l X F X T
采用3个一维卷积核,分别为( k 1 , v 1 ) ( k 2 , v 2 ) ( k 3 , v 3 ) 图3 所示。
图3
图3
一维门控卷积结构
Fig.3
Structure of one-dimensional gated convolution
最后,将卷积后的数据进行concat操作,获得时序嵌入序列 T F : T l ∈ R 24 , F l ∈ R 24 l =1, 2, 3。其运算过程如下:
T 1 i = ∑ m X T m + i k 1 m ⊙ σ ∑ m X T ( m + i ) v 1 ( m ) (1)
T 2 ( i ) = ∑ m X T ( m + i ) k 2 ( m ) ⊙ σ ∑ m X T ( m + i ) v 2 ( m ) (2)
T 3 ( i ) = ∑ m X T ( m + i ) k 3 ( m ) ⊙ σ ∑ m X T ( m + i ) v 3 ( m ) (3)
F 1 i = ∑ m X F ( m + i ) k 1 ( m ) ⊙ σ ∑ m X F ( m + i ) v 1 ( m ) (4)
F 2 ( i ) = ∑ m X F ( m + i ) k 2 ( m ) ⊙ σ ∑ m X F ( m + i ) v 2 ( m ) (5)
F 3 ( i ) = ∑ m X F ( m + i ) k 3 ( m ) ⊙ σ ∑ m X F ( m + i ) v 3 ( m ) (6)
式中:m m = 1 , … , N - 1 - L σ
通过多个卷积函数运算和拼接操作后,模型获得不同周期的时间序列信息和频率序列信息。
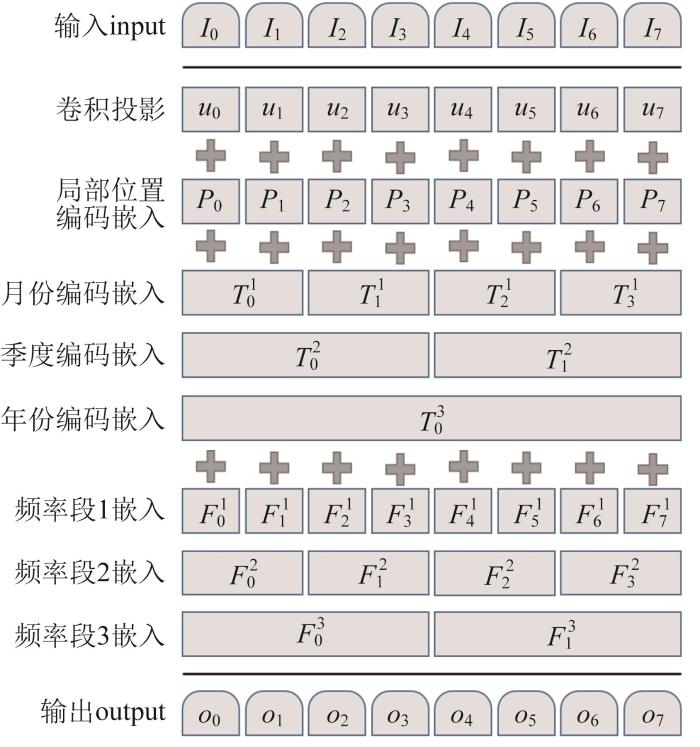
在Transformer模型中,编码器的输入由两部分组成,分别是词编码矩阵 I I ∈ R n × d x P P ∈ R n × d x ) n P P P k 表示偶数位置,2k +1表示奇数位置,p os 表示观察点在输入序列中的位置,0≤p os <L /2,则:
P 2 k = s i n p o s 2 L 2 k / d m o d e l P 2 k + 1 = c o s p o s 2 L 2 k / d m o d e l (7)
除了位置编码,编码层注意力输入的特征序列还包括时间序列信息和频率序列信息。考虑到时间特征和频率特征在实际应用中的有效性,采用时间序列数据,提取时间戳中的月位置嵌入、季度位置嵌入以及时间段内的订单频率嵌入,将这些编码为叠加的位置编码,共同构成可学习的嵌入[17 ] 。所提出的位置嵌入方法主要由以下4个部分构成:1)销量经过卷积得到的标量;2)sin函数固定的局部位置编码;3)由数据段对应时刻的月份、季度、年度得到的全局位置编码 T F
对上述4个主要部分进行叠加,作为时序和频率嵌入信息输入模型,使网络能有效捕捉时间帧之间的局部和全局相关性。其公式如下:
X i = X t + P L × ( t - 1 ) + i + ∑ p T L × ( t - 1 ) + i p + ∑ q F L × ( t - 1 ) + i q (8)
式中:X t L 的销量序列,t 为时间窗口序列数,p q i ∈ [ 1 , 6 ]
将带有特征指标的销量时间序列作为模型的输入,并将周期信息注入输入的时间序列,供模型学习相关事件知识。
将前一个时间窗口的所有特征与其在不同时间戳尺度的时刻数据相加,构成新的特征数据序列并将它输入网络,使模型学习历史数据中的模式,从而帮助预测下一个时间窗口。采用上述方法对特征进行周期性增强后,模型得以测量输入信号间的时延相似度,并对多个相似的历史子序列进行聚合后输出。特征数据序列输入网络如图4 所示。
图4
图4
特征数据序列输入网络
Fig.4
Input network for feature data sequences
1.2 基于时序-频率自注意力机制的编码器结构
编码完成后,为了确保序列中每一条信息的长度都相同,需要对数据进行特征缩放,如式(9)所示。
X i = R e L U I i × W i n + b i n (9)
式中:W i n I i b i n
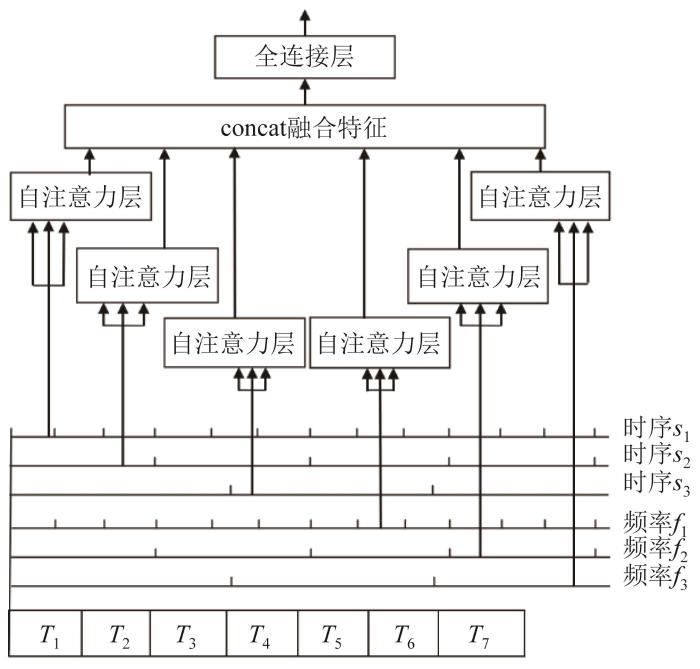
经过缩放后的特征被送入自注意力机制层并由其完成对输入特征的编码。在编码层的时序-频率多头自注意力模块结构如图5 所示。
图5
图5
时序-频率多头自注意力模块结构
Fig.5
Structure of timing-frequency multi-head self-attention module
该时序-频率自注意力模块结构的 Q K V
q i = W i q ⋅ X i k i = W i k ⋅ X i v i = W i v ⋅ X i i = 1 , 2 , … , t (10)
定义6个映射矩阵W i q ∈ R 24 × 36 Q q i W i k ∈ R 24 × 36 K k i W i v ∈ R 24 × 36 V v i
对每个注意力头(q i k i v i ) 进行一次自注意力运算,得到结果h i h i W 0 = R 24 × 24 H o u t
h i = a t t e n t i o n W i q q , W i k k , W i v v (11)
a t t e n t i o n Q , K , V = s o f t m a x Q K T d x V (12)
H o u t = c o n c a t h 1 , ⋯ , h 6 W 0 (13)
基于上述分析可知, Q K V Q K V
得到自注意力层后,下一步操作是层归一化(LayerNorm)与残差连接(Add)。通过对层激活值的归一化,可以加速模型的训练过程,使其更快地收敛,避免梯度消失问题。记层归一化结果为L N
L N = L a y e r N o r m a l i z a t i o n H o u t + X i (14)
接下来是一个基于位置的全连接前馈神经网络。全连接前馈神经网络包含2次ReLU激活函数的线性变换,F 1 F 2
F 1 = R e L U x W 1 + b 1 (15)
F 2 = R e L U F 1 W 2 + b 2 (16)
X o u t = L a y e r N o r m a l i z a t i o n F 2 + L N (17)
式中:x ∈ R 1 × 36 W 1 ∈ R 36 × 36 、 W 2 ∈ R 36 × 36 b 1 ∈ R 1 × 36 、 b 2 ∈ R 1 × 36
由式(4)至式(6)可得单个样本的输出X o u t ∈ R 1 × 36
综上所述,可以构建出SFTransformer模型的编码器结构。SFTransformer模型的编码模块中连接了4个编码器。通过使用多个编码器,可以使模型更有效地处理输入数据并生成更准确的输出。
1.3 基于时序-频率自注意力机制的解码器结构
原始的Transformer模型用于解决NLP(neuro-linguistic programming,神经语言程序学)问题,采用了双向注意力机制,而时间序列具有单向性。为了解决这个问题,需要在解码器第1层自注意力模块使用掩码机制,以屏蔽来自后续时间步的信息,可以表示为:
H m a s k = s o f t m a x Q i × K i T d x ⋅ 1 ⋯ 0 ⋮ ⋮ 1 ⋯ 1 × V i (18)
解码器第1层自注意力模块的输入来自上一层的输出,并附带了掩码机制。将式(18)中Q i K i T
解码器第2层自注意力模块的输入来自两部分:第1部分来自上一层解码器的输出,但仅作为该层的查询矩阵 Q K V
由上可得,解码阶段的每个时间步都会输出一个输出序列的元素,接下来的每个时间步都重复这个过程。每个时间步的输出在下一个时间步被提供给解码器,最后部分是输出预测结果,通过解码器得到一个最终向量。经过线性层、全连接层和Softmax函数对向量进行计算,假设预测步长L =4,则编码器层输出序列X o u t = ( x o u t 1 x o u t 2 ⋯ x o u t ( s + 4 ) ) s 为序列数。三步时间独立线性层有3个矩阵W i ∈ R 24 × 4 X o u t X ' o u t = ( x o u t ( s + 1 ) x o u t ( s + 2 ) x o u t ( s + 3 ) x o u t ( s + 4 ) ) W i Y ^ = ( y ^ s + 1 y ^ s + 2 y ^ s + 3 y ^ s + 4 )
y ^ s + 1 = l i n e a r x o u t ( s + 1 ) , W 1 (19)
y ^ s + 2 = l i n e a r x o u t ( s + 2 ) , W 2 (20)
y ^ s + 3 = l i n e a r x o u t ( s + 3 ) , W 3 (21)
y ^ s + 4 = l i n e a r x o u t ( s + 4 ) , W 4 (22)
模型在训练过程中采用均方误差(mean-square error, MSE)函数作为损失函数。将时间序列输入网络,将得到的预测评分与真实评分进行比较,计算损失。损失从解码器输出并反向传播到整个模型。
2 实验分析
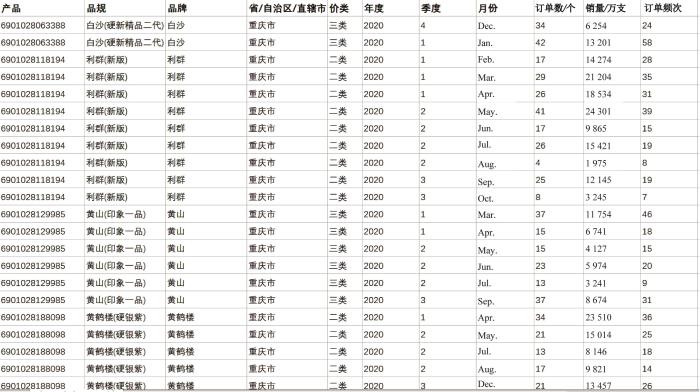
实验数据来源于某复杂产品制造企业的销售数据。收集了各产品2017—2020年的销售数据,其中2017—2019年的销量数据作为模型训练集,2020年的销量数据作为模型测试集。由经过特征筛选的产品品规、品牌、归属省份、所属价类、月订单数、月销量、月订单频次等数据构成销量预测的数据集。企业部分销售数据如图6 所示。
图6
图6
某复杂产品制造企业销售数据集
Fig.6
Sales dataset of a complex product manufacturing enterprise
为了保证实验的准确性,在数据集中删除了2017—2019年过少的销售量,例如删除了月订单数低于3次、月销量低于5万支的数据。经过数据筛选,得到了591个产品序列、408 241条订单数据,将它作为输入数据。由于数据之间的结构不同,原始特征数据的量纲相差较大,在将数据输入模型前对原始数据进行标准化和归一化处理,以消除量纲对模型分析的影响。
实验环境中,CPU(central processing unit,中央处理器)采用AMD Ryzen 9 5900HX with Radeon Graphics,GPU(graphics processing unit,图形处理器)采用NVIDIA GTX3070 8G,内存为32G,开发环境为Pytorch 1.13.0+cu116,采用Jupyter notebook平台。
实验中,分别用均方误差E SM 、平均绝对误差E MA 、均方根误差E RSM 来评估模型的性能[18 -20 ] 。E SM 、E MA 、E RSM 的值越小,代表模型的预测性能越好。
设置输入样本的步长为36,每个数据集的预测长度分为4和12两组。SFTransformer模型参数设置如表1 所示。
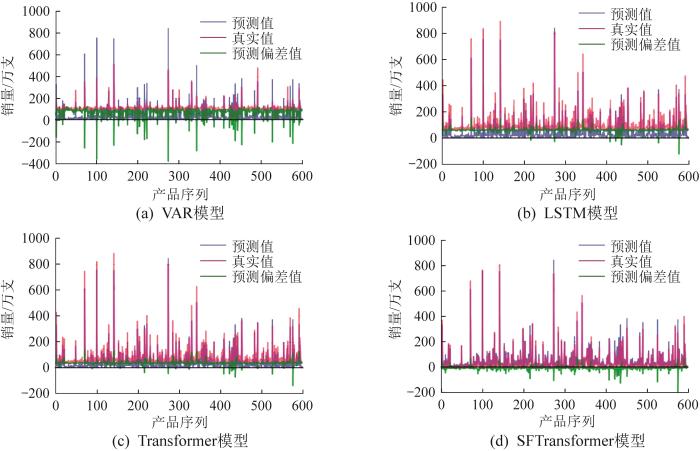
实验中选取VAR(vector autoregressive,向量自回归)模型、LSTM模型、Transformer模型等3个常用的时间序列预测模型来与本文提出的SFTransformer模型作对比实验。SFTransformer模型与以上3个模型预测性能的对比如表2 所示。由表可知,SFTransformer模型具有更稳定的长期预测性能。通过关注时序与频率特征,可以关注到其他模型无法关注到的订单频率信息,有较好的预测性能。SFTransformer模型的预测误差大大小于VAR模型和LSTM模型,并小幅小于Transformer模型,充分说明了时序-频率自注意力机制在时间序列预测问题上的优越性。
VAR模型、LSTM模型、Transformer模型和SFTransformer模型对产品销量的预测结果如图7 所示。由图可知:SFTransformer模型的预测偏差极小,预测值与真实值很接近;Transformer模型的预测偏差较小,可以较好地预测销量趋势;LSTM模型的预测值大部分离容错区间较远;VAR模型在此类问题上无法预测相关趋势,预测值与真实值出现了极大的偏离。可见,SFTransformer模型对复杂产品订单长时间序列预测的结果好于Transformer模型。
图7
图7
各模型对产品销量的预测结果
Fig.7
Prediction results of product sales volume by each model
3 结 论
本文介绍了融合多主体需求频率特征的复杂产品全生命周期价值链协同设计方法。基于Transformer模型,构建了基于改进注意力机制的价值链高频需求预测模型——SFTransformer模型。以复杂产品全生命周期价值链中的订单需求为预测目标,在SFTransformer模型中设计了时序-频率多头自注意力机制。该机制将基于时序的订单数据的不同订单频率分别对应不同的注意力头来关注订单数据的时序特征和频率特征,结合了Embedding输入处理和Transformer模型结构。利用SFTransformer模型对实际的企业订单数据进行了预测,取得了较好效果,表明SFTransformer模型在一定程度上提升了预测准确率,说明融合多主体需求频率特征的复杂产品全生命周期价值链协同设计方法是有效的。
在数字经济时代,随着制造行业业务模式的增加,复杂产品价值链上业务数据的复杂度不断提高。本文针对复杂产品全生命周期价值链上多主体业务进行研究,挖掘数据中蕴含的价值。数据是分析问题的前提,数据集成与融合效果的好坏会直接影响后续工作的展开。因此,在后续的研究中,需要综合考虑数据来源及特征优化等相关问题,以确保数据集的准确性和高相关性。此外,企业在进行产品开发中会遇到很多复杂场景,因此,在后续的研究中,应该考虑融合多种预测模型的价值链协同设计,为实现复杂产品价值最大化提供更多的参考和指导,从而为企业的提效增益助力。
参考文献
View Option
[2]
王静 ,曹春正 基于贝叶斯分层自回归时空模型的北京PM2.5 预测
[J].南京信息工程大学学报(自然科学版) ,2023 ,15 (1 ):34 -41 .
[本文引用: 1]
WANG J CAO C Z Prediction of PM2.5 concentration in Beijing based on Bayesian hierarchical autoregressive spatio-temporal model
[J]. Journal of Nanjing University of Information Science and Technology (Natural Science Edition) , 2023 , 15 (1 ): 34 -41 .
[本文引用: 1]
[3]
陈然 指数平滑与自回归融合预测模型及应用研究
[D]. 阜新 :辽宁工程技术大学 ,2021 .
[本文引用: 1]
CHEN R Index smoothing and autoregressive fusion forecasting model and its empirical study
[D]. Fuxin : Liaoning Technical University , 2021 .
[本文引用: 1]
[5]
高塔 基于改进贝叶斯网络的高维数据本地差分隐私方法的研究
[D].北京 :北京交通大学 ,2021 .
[本文引用: 1]
GAO T Research on local differential privacy method for high-dimensional data based on improved Bayesian network
[D]. Beijing : Beijing Jiaotong University , 2021 .
[本文引用: 1]
[6]
MNIH V HEESS N GRAVES A et al Recurrent models of visual attention
[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Cambridge . Cambridge, Massachusetts, USA : MIT Press , 2014 : 2204 -2212 .
[本文引用: 1]
[7]
武晋鹏 基于样本精选与BERT模型引导的图像情感分析研究
[D].南昌 :华东交通大学 ,2021 .
[本文引用: 1]
WU J P Image sentiment analysis based on sample refinement and BERT guided
[D]. Nanchang : East China Jiaotong University , 2021 .
[本文引用: 1]
[8]
XIANG Y FOX D DA-RNN: semantic mapping with data associated recurrent neural networks
[C]//13th Conference on Robotics-Science and Systems , Cambridge, Massachusetts, Jul. 12 -16 , 2017 .
[本文引用: 1]
[9]
QIN Y SONG D CHEN H et al A dual-stage attention-based recurrent neural network for time series prediction
[EB/OL]. [2023-10-06 ]..
URL
[本文引用: 1]
[10]
HOCHREITER S Long short-term memory
[J]. Neural Computation , 1997 (9 ): 1735 -1780 .
[本文引用: 1]
[11]
SESTI N GARAU-LUIS J J CRAWLEY E et al Integrating LSTMs and GNNs for COVID-19 forecasting
[J]. arXiv preprint arXiv:, 2021 .
[本文引用: 1]
[12]
王素 基于深度学习的时间序列预测算法研究与应用
[D].成都 :电子科技大学 ,2022 .
[本文引用: 1]
WANG S Research and application of time series prediction algorithm based on deep learning
[D]. Chengdu : University of Electronic Science and Technology of China , 2022 .
[本文引用: 1]
[13]
CHO K VAN MERRIENBOER B BAHDANAU D et al On the properties of neural machine translation: Encoder-Decoder approaches
[EB/OL]. [2023-10-06 ]. .
URL
[本文引用: 1]
[14]
VASWANI A SHAZEER N PARMAR N Attention is all you need
[EB/OL]. [2023-10-06 ]..
URL
[本文引用: 1]
[15]
LIN L LUO H HUANG R et al Recurrent models of visual co-attention for person re-identification
[J]. IEEE Access , 2019 , 7 : 8865 -8875 .
[本文引用: 1]
[16]
陈超 基于神经网络的多变量时间序列预测
[D].成都 :电子科技大学 ,2022 .
[本文引用: 1]
CHEN C Multivariate time prediction based on neural network
[D]. Chengdu : University of Electronic Science and Technology of China , 2022 .
[本文引用: 1]
[17]
MIKOLOV T SUTSKEVER I KAI C , et al Distributed representations of words and phrases and their compositionality
[C]//NIPS'13: Proceedings of the 26th International Conference on Neural Information Processing Systems: Volume 2 . New York : ACM , 2013 : 3111 -3119 .
[本文引用: 1]
[18]
WANGA R LOUA J JIANGA Y Session-based recommendation with time-aware neural attention network
[J]. Expert Systems with Applications , 2022 , 210 : 118395 .
[本文引用: 1]
[19]
陈士超 ,郁滨 面向术语抽取的双阈值互信息过滤方法
[J].计算机应用 ,2011 ,31 (4 ):1070 -1073 . doi:10.3724/sp.j.1087.2011.01070
DOI:10.3724/sp.j.1087.2011.01070
CHEN S C YU B Method of mutual information filtration with dual-threshold for term extraction
[J]. Journal of Computer Applications , 2011 , 31 (4 ): 1070 -1073 .
DOI:10.3724/sp.j.1087.2011.01070
[20]
曹昀炀 基于Transformer的选股因子挖掘
[D].上海 :华东师范大学 ,2022 .
[本文引用: 1]
CAO Y Y Based on Transformer stock factor construction
[D]. Shanghai : East China Normal University , 2022 .
[本文引用: 1]
时间序列预测方法综述
1
2019
... 随着大数据技术的迅速发展,复杂产品的订单数据资源得以有效保留.这些数据资源的背后蕴含了产品价值链上多主体的市场营销信息,而大多数企业往往无法高效率、低成本地运用销售数据来辅助商业决策.如何利用这些销售数据指导企业的生产决策,仍是企业面临的重要课题.通常来讲,复杂产品的销量与天气、交通运输量等相似,是一个时间序列的预测问题[1 ] . ...
时间序列预测方法综述
1
2019
... 随着大数据技术的迅速发展,复杂产品的订单数据资源得以有效保留.这些数据资源的背后蕴含了产品价值链上多主体的市场营销信息,而大多数企业往往无法高效率、低成本地运用销售数据来辅助商业决策.如何利用这些销售数据指导企业的生产决策,仍是企业面临的重要课题.通常来讲,复杂产品的销量与天气、交通运输量等相似,是一个时间序列的预测问题[1 ] . ...
基于贝叶斯分层自回归时空模型的北京PM2.5 预测
1
2023
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
基于贝叶斯分层自回归时空模型的北京PM2.5 预测
1
2023
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
指数平滑与自回归融合预测模型及应用研究
1
2021
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
指数平滑与自回归融合预测模型及应用研究
1
2021
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
基于SVM和RBF神经网络的CFB NOx生成预测模型
1
2020
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
基于SVM和RBF神经网络的CFB NOx生成预测模型
1
2020
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
基于改进贝叶斯网络的高维数据本地差分隐私方法的研究
1
2021
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
基于改进贝叶斯网络的高维数据本地差分隐私方法的研究
1
2021
... 时序预测的主要方法分为以下3种:数学统计方法、传统机器学习方法和深度学习方法.传统的数学统计方法主要采用统计学知识对数据时序中蕴含的发展过程、方向和趋势进行建模并预测,其常见的模型有移动平均(moving average)模型[2 ] 和自回归(auto regressive)模型[3 ] 等.然而,其较低的表达能力导致不能处理复杂数据中的宏观趋势预测问题和非线性关系,因此预测准确率不高.传统机器学习方法包括支持向量机[4 ] 、贝叶斯网络等[5 ] ,其克服了数学统计方法的缺点,在时序预测中取得了良好效果.但由于复杂产品销售数据具有季节性、动态性、周期性的特点及行业本身的特殊特征,序列数据往往存在很多干扰项,使得传统机器学习方法较难进行精准的预测. ...
Recurrent models of visual attention
1
2014
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
基于样本精选与BERT模型引导的图像情感分析研究
1
2021
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
基于样本精选与BERT模型引导的图像情感分析研究
1
2021
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
DA-RNN: semantic mapping with data associated recurrent neural networks
1
16
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
A dual-stage attention-based recurrent neural network for time series prediction
1
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
Long short-term memory
1
1997
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
Integrating LSTMs and GNNs for COVID-19 forecasting
1
2021
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
基于深度学习的时间序列预测算法研究与应用
1
2022
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
基于深度学习的时间序列预测算法研究与应用
1
2022
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
On the properties of neural machine translation: Encoder-Decoder approaches
1
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
Attention is all you need
1
... 深度学习方法可以将有效特征从大量原始数据中抽取出来,因此通过深度学习方法建立的模型的实用性和准确度较高.循环神经网络(recursive neural network,RNN)[6 ] 具有较强记忆性、参数共享且图灵完备(Turing completeness),在对序列数据的非线性特征进行学习时具有一定优势.RNN多用于自然语言处理领域,也被用于时序预测领域[7 ] .基于双阶段注意力机制的RNN模型是经典的时序预测模型[8 ] ,其加入了注意力机制,编码时自适应选择相关程度高的序列信息,解码时考虑了编码阶段所有时间步的隐状态而非传统方法中的定长向量,解决了长期依赖问题[9 ] .长短期记忆(long short-term memory,LSTM)网络[10 -11 ] 是一类特殊的RNN,改善了RNN的长期依赖问题,解决了RNN训练中的梯度问题.LSTM网络能通过隐状态长期保留时序信息,常用于单变量和多变量序列数据的分析和预测[12 ] .门控循环单元(gated recurrent unit, GRU)[13 ] 是简化版的LSTM网络,它将输入门和遗忘门结合在一起,形成一个更新门.GRU比LSTM网络的参数少,大大降低了复杂度.2017年提出的Transformer模型[14 ] 对长期预测的效果较好,虽然模型较为复杂,但对序列数据中的长期依赖关系拥有比LSTM网络更强大的建模能力,更加适用于时序建模. ...
Recurrent models of visual co-attention for person re-identification
1
2019
... Transformer模型基于编码器-解码器结构,其特点是能够有效地捕捉长期依赖关系,并利用多头自注意力机制挖掘序列数据的内在关联性[15 ] .相比于LSTM等序列模型,Transformer模型可以一次性输入时间序列并进行并行计算,从而大大缩短计算时间,并且能够对长期和短期时序特征进行建模. ...
基于神经网络的多变量时间序列预测
1
2022
... 复杂产品的高周转率和短保质期带来了较高的订单频率,而传统模型更多考虑的是订单数据的时序和销量对销售周期的影响,忽略了订单频率中蕴含的细节信息.为了提取数据集中的频率信息,采取一维门控卷积操作来提取频率序列数据.一维门控卷积操作一般运用在序列数据上,不同大小的卷积操作代表着序列对不同频率的依赖[16 ] . ...
基于神经网络的多变量时间序列预测
1
2022
... 复杂产品的高周转率和短保质期带来了较高的订单频率,而传统模型更多考虑的是订单数据的时序和销量对销售周期的影响,忽略了订单频率中蕴含的细节信息.为了提取数据集中的频率信息,采取一维门控卷积操作来提取频率序列数据.一维门控卷积操作一般运用在序列数据上,不同大小的卷积操作代表着序列对不同频率的依赖[16 ] . ...
Distributed representations of words and phrases and their compositionality
1
2013
... 除了位置编码,编码层注意力输入的特征序列还包括时间序列信息和频率序列信息.考虑到时间特征和频率特征在实际应用中的有效性,采用时间序列数据,提取时间戳中的月位置嵌入、季度位置嵌入以及时间段内的订单频率嵌入,将这些编码为叠加的位置编码,共同构成可学习的嵌入[17 ] .所提出的位置嵌入方法主要由以下4个部分构成:1)销量经过卷积得到的标量;2)sin函数固定的局部位置编码;3)由数据段对应时刻的月份、季度、年度得到的全局位置编码 T F
Session-based recommendation with time-aware neural attention network
1
2022
... 实验中,分别用均方误差E SM 、平均绝对误差E MA 、均方根误差E RSM 来评估模型的性能[18 -20 ] .E SM 、E MA 、E RSM 的值越小,代表模型的预测性能越好. ...
基于Transformer的选股因子挖掘
1
2022
... 实验中,分别用均方误差E SM 、平均绝对误差E MA 、均方根误差E RSM 来评估模型的性能[18 -20 ] .E SM 、E MA 、E RSM 的值越小,代表模型的预测性能越好. ...
基于Transformer的选股因子挖掘
1
2022
... 实验中,分别用均方误差E SM 、平均绝对误差E MA 、均方根误差E RSM 来评估模型的性能[18 -20 ] .E SM 、E MA 、E RSM 的值越小,代表模型的预测性能越好. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}