SAGE: Slam with appearance and geometry prior for endoscopy
1
2022
... 医学图像配准是现代计算机辅助诊断应用系统必不可少的模块,是实现如手术导航[1]、图像重建[2]、图谱构建[3]等自动化分析任务的重要前提.从数学的角度看,医学图像配准就是在特定的相似性目标测度函数下求解空间变换,使得变换后待配准图像之间的相似性达到最大或差异性达到最小.从图像变形的角度看,医学图像配准通常可分为刚性配准和变形配准.前者主要用于估计骨骼等刚性物体之间的整体变化;后者侧重于估计局部差异,如器官的运动.与刚体配准只需求解平移、旋转、缩放等有限参数不同,变形配准旨在获得从运动图像到固定图像的优化多参数可变形场[4]. ...
Self-supervised natural image reconstruction and large-scale semantic classification from brain activity
1
2022
... 医学图像配准是现代计算机辅助诊断应用系统必不可少的模块,是实现如手术导航[1]、图像重建[2]、图谱构建[3]等自动化分析任务的重要前提.从数学的角度看,医学图像配准就是在特定的相似性目标测度函数下求解空间变换,使得变换后待配准图像之间的相似性达到最大或差异性达到最小.从图像变形的角度看,医学图像配准通常可分为刚性配准和变形配准.前者主要用于估计骨骼等刚性物体之间的整体变化;后者侧重于估计局部差异,如器官的运动.与刚体配准只需求解平移、旋转、缩放等有限参数不同,变形配准旨在获得从运动图像到固定图像的优化多参数可变形场[4]. ...
CoTr: Efficiently bridging CNN and transformer for 3D medical image segmentation
2
2021
... 医学图像配准是现代计算机辅助诊断应用系统必不可少的模块,是实现如手术导航[1]、图像重建[2]、图谱构建[3]等自动化分析任务的重要前提.从数学的角度看,医学图像配准就是在特定的相似性目标测度函数下求解空间变换,使得变换后待配准图像之间的相似性达到最大或差异性达到最小.从图像变形的角度看,医学图像配准通常可分为刚性配准和变形配准.前者主要用于估计骨骼等刚性物体之间的整体变化;后者侧重于估计局部差异,如器官的运动.与刚体配准只需求解平移、旋转、缩放等有限参数不同,变形配准旨在获得从运动图像到固定图像的优化多参数可变形场[4]. ...
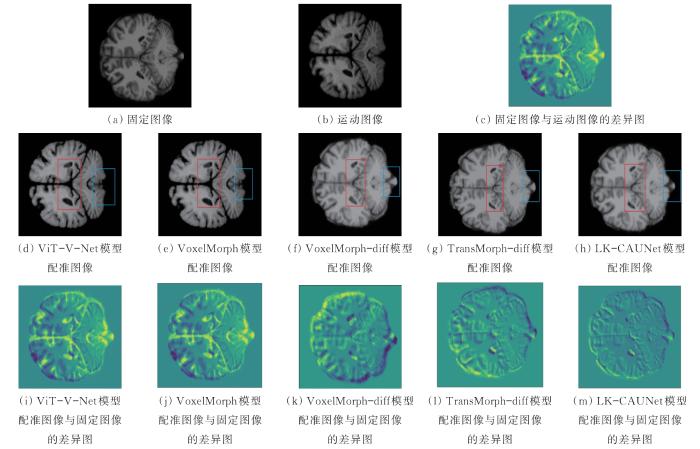
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Deformable medical image registration: A survey
1
2013
... 医学图像配准是现代计算机辅助诊断应用系统必不可少的模块,是实现如手术导航[1]、图像重建[2]、图谱构建[3]等自动化分析任务的重要前提.从数学的角度看,医学图像配准就是在特定的相似性目标测度函数下求解空间变换,使得变换后待配准图像之间的相似性达到最大或差异性达到最小.从图像变形的角度看,医学图像配准通常可分为刚性配准和变形配准.前者主要用于估计骨骼等刚性物体之间的整体变化;后者侧重于估计局部差异,如器官的运动.与刚体配准只需求解平移、旋转、缩放等有限参数不同,变形配准旨在获得从运动图像到固定图像的优化多参数可变形场[4]. ...
Nonrigid registration using free-form deformations: Application to breast MR images
1
1999
... 传统的医学图像配准方法通常通过迭代优化生成理想的空间变换,需要使用运动图像与固定图像之间的相似性测度确定迭代过程是否达到最优.运用迭代优化技术的FFD[5]、Demons[6]、ANTS[7]、Flash[8]和ADMM[9]等方法已被应用于变形图像配准.然而,这种基于优化的方法需对每个图像进行精细的超参数调优,非常耗时,限制了其在实时和大规模数据配准中的应用. ...
Diffeomorphic demons: Efficient non-parametric image registration
1
2009
... 传统的医学图像配准方法通常通过迭代优化生成理想的空间变换,需要使用运动图像与固定图像之间的相似性测度确定迭代过程是否达到最优.运用迭代优化技术的FFD[5]、Demons[6]、ANTS[7]、Flash[8]和ADMM[9]等方法已被应用于变形图像配准.然而,这种基于优化的方法需对每个图像进行精细的超参数调优,非常耗时,限制了其在实时和大规模数据配准中的应用. ...
A reproducible evaluation of ANTs similarity metric performance in brain image registration
1
2011
... 传统的医学图像配准方法通常通过迭代优化生成理想的空间变换,需要使用运动图像与固定图像之间的相似性测度确定迭代过程是否达到最优.运用迭代优化技术的FFD[5]、Demons[6]、ANTS[7]、Flash[8]和ADMM[9]等方法已被应用于变形图像配准.然而,这种基于优化的方法需对每个图像进行精细的超参数调优,非常耗时,限制了其在实时和大规模数据配准中的应用. ...
Fast diffeomorphic image registration via fourier-approximated lie algebras
1
2019
... 传统的医学图像配准方法通常通过迭代优化生成理想的空间变换,需要使用运动图像与固定图像之间的相似性测度确定迭代过程是否达到最优.运用迭代优化技术的FFD[5]、Demons[6]、ANTS[7]、Flash[8]和ADMM[9]等方法已被应用于变形图像配准.然而,这种基于优化的方法需对每个图像进行精细的超参数调优,非常耗时,限制了其在实时和大规模数据配准中的应用. ...
Nesterov accelerated ADMM for fast diffeomorphic image registration
1
2021
... 传统的医学图像配准方法通常通过迭代优化生成理想的空间变换,需要使用运动图像与固定图像之间的相似性测度确定迭代过程是否达到最优.运用迭代优化技术的FFD[5]、Demons[6]、ANTS[7]、Flash[8]和ADMM[9]等方法已被应用于变形图像配准.然而,这种基于优化的方法需对每个图像进行精细的超参数调优,非常耗时,限制了其在实时和大规模数据配准中的应用. ...
Learn2Reg: Comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
1
2023
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
VoxelMorph: A learning framework for deformable medical image registration
2
2019
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Topology-preserving shape reconstruction and registration via neural diffeomorphic flow
1
2022
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
Recursive cascaded networks for unsupervised medical image registration
0
2019
Fast symmetric diffeomorphic image registration with convolutional neural networks
0
2020
Learning a model-driven variational network for deformable image registration
0
2021
CycleMorph: Cycle consistent unsupervised deformable image registration
2
2021
... IXI数据集的固定图像为576幅T1加权脑MRI图像,运动图像为脑部MRI数据[16],使用FreeSurfer预处理.将所有图像尺寸裁剪为160×192×224.将数据集划分为403,58和115幅,分别用于训练、验证和测试.同时,使用包含30个解剖结构的标签图评估配准性能. ...
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
TransMorph: Transformer for unsupervised medical image registration
6
2022
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
... 同时,针对图像配准任务,利用微分同胚映射计算平滑且可逆的变形场,从而保证运动图像变形但不丢失显著特征,即在模型输出的稳定变形场的基础上,采用7个缩放和平方层计算积分,以诱导异胚化,最终变形场可表示为[17]. ...
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
... [17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
... [17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
... [17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
UNet vs transformer: Is UNet outdated in medical image registration?
1
2022
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
ViT-V-Net: Vision Transformer for Unsupervised Volumetric Medical Image Registration
2
2021-04-13
... 近年来,基于深度学习的方法在医学图像配准领域迅速发展.试图通过学习运动图像和固定图像中变化的位移矢量场的通用表示,将运动图像映射到固定图像[10].最典型的为VoxelMorph[11],采用UNet风格的架构估计密集的空间变形场.因只需在推理过程中进行一次前向传播,其速度比传统方法快几个数量级.此后,大量针对不同配准任务的基于深度学习的方法被相继提出[12-18].然而,具有挑战性的应用和计算机视觉的最新进展表明,卷积操作的有效接受场受卷积核大小的限制,卷积神经网络在建模图像的远程空间关系上具有局限性.因此,自注意力机制具有大尺寸有效接受野的Transformer成为研究热点.CHEN等[19]在V-Net风格的卷积网络中采用vision transformer块提出了ViT-V-Net,并对其进行了改进,用swin-transformers取代VoxelMorph中的基本卷积块,进一步提出了TransMorph[17],使模型能够捕获远程空间信息,提高配准性能.虽然这些方法证实了transformer在图像配准中的有效性,但需大量的参数和GPU内存,大大增加了计算复杂度. ...
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
基于双通道级联注意力网络的医学图像配准
1
2021
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
基于双通道级联注意力网络的医学图像配准
1
2021
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
基于残差注意力机制的点云配准算法
1
2022
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
基于残差注意力机制的点云配准算法
1
2022
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
An unsupervised learning model for deformable medical image registration
2
2018
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
End-to-end unsupervised deformable image registration with a convolutional neural network
1
2017
... 卷积神经网络在理解特征之间的空间对应关系方面能力有限,虽然基于transformer的配准模型可在一定程度上解决这一问题,但是巨大的参数量使模型在很多配准任务中难以实现.受transformer的启发,嵌入自注意力机制的模型在图像配准任务中表现出色.为提高卷积神经网络在医学图像中的配准精度,张纠等[20]提出一种双通道级联注意力网络,在配准过程中引入注意力机制进行特征权重分配,增强网络的特征表达能力.秦庭威等[21]将残差注意力机制引入动态图卷积网络,使得点云空间信息被有效利用,并减少了信息损失.虽然这些深度学习网络在单幅图像特征表示上能力较强,但在可变形医学图像配准中对图像对的特征提取和匹配仍存在局限性.如图1所示,可变形医学图像配准方法先将移动图像与固定图像融合,模拟单幅图像输入条件,再将融合后的图像输入运动-固定特征的单幅图像网络,出现混合区域内的特征失真[22-23].这些方法因将特征提取和特征匹配过程相混合,导致混合区域特征失真和弱对齐,从而无法实现图像对之间的一一对应.最终导致关键结构缺失和配准细节较差. ...
Non-local neural net-works
1
2018
... 采用交叉注意力模块融合大内核多尺度特征提取卷积块,从运动图像和固定图像中提取图像特征,该图像特征与计算单幅图像自我注意力的非局部块不同[24].交叉注意力模块旨在建立两幅不同图像特征之间的空间对应关系,该模块的结构如图5所示.模块的两个输入特征映射分别记为原始输入和交叉输入.L,W和H表示每个三维特征扁平化后的尺寸.交叉特征可以表示为 ...
Open access series of imaging studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults
1
2007
... 为了评估提出的配准方法,使用OASIS数据集[25]和IXI数据集(https://brain-development.org/ixi-dataset)进行验证.OASIS数据集由413个T1加权MRI图像组成.使用Learn2Reg 2021挑战提供的预处理OASIS数据集进行主体间脑配准.每次MRI脑部扫描均需经过颅骨剥离、对齐、归一化处理,分辨率为160×192×224.在该数据集中,394幅图像用于训练,19幅图像对用于测试.同时,使用35个解剖结构的标签掩膜,使用Dice得分等指标评估配准性能. ...
An open source multivariate framework for n-tissue segmentation with evaluation on public data
1
2011
... 对配准图像与固定图像进行定量和定性比较,评估不同方法的配准性能.Dice得分是一种基于重叠度的比较方法,以其作为定量评估指标.首先,使用ANTs Atropos分割方法将固定图像和配准图像分割为脑脊液、白质、灰质和背景4个部分[26].然后,计算每部分的Dice得分,取其平均值.固定图像与配准图像之间的Dice得分为 ...
Symmetric diffeomorphic image registration with cross-correlation: Evaluating automated labeling of elderly and neurodegenerative brain
1
2008
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Fast free-form deformation using graphics processing units
1
2010
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Computing large deformation metric mappings via geodesic flows of diffeomorphisms
1
2005
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Multi-modal multi-atlas segmentation using discrete optimisation and self-similarities
1
2015
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Unsupervised learning of probabilistic diffeomorphic registration for images and surfaces
1
2019
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Learning diffeomorphic and modality-invariant registration using B-splines
1
2021
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
1
2021
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...
NNFormer: Interleaved trans-former for volumetric segmentation
1
2023
... 将LK-CAUNet模型与18种具有较好配准性能的Affine、SyN[27]、NiftyReg[28]、LDDMM[29]、deedsBCV[30]、VoxelMorph[11, 22]、VoxelMorph-diff[31]、CycleMorph[16]、MIDIR[32]、ViT-V-Net[19]、CoTr[3]、PVT[33]、nnFormer[34]、TransMorph[17]、TransMorph-Bayes[17]、TransMorph-bspl[17]、UNet和TransMorph-diff[17]模型进行了比较,结果如表2所示.其中,前5种为非深度学习配准方法,为平衡配准精度与运行时间,通常根据经验设定其超参数.后13种为基于深度学习的配准方法,为保证结果的准确性,通常选择由MSE和扩散正则化项组成的损失函数进行MRI配准. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}