


TOFD(time of flight diffraction,衍射时差法)超声检测技术凭借可准确测量超声波在材料内部传播时间的能力[7],能够精确量化焊缝缺陷的深度与高度特征,进而实现缺陷的三维高精度定位[8]。然而,需要注意的是,TOFD焊缝缺陷图像存在以下特征。1)成像机制复杂。超声波在焊缝中传播时,遇到不同的结构和缺陷会产生反射、折射和衍射信号,这些信号相互叠加、干涉。例如,当焊缝中同时存在多种类型的缺陷时,不同衍射信号相互交织,导致TOFD图像的干扰显著,难以准确识别单个缺陷。2)分辨率有限。当检测深度增大时,超声波信号的扩散和衰减导致TOFD图像的细节逐渐模糊。此外,对于微小缺陷或相邻较近缺陷,TOFD图像很难清晰地呈现其边界特征信息。3)噪声干扰显著。由于焊接环境、焊接材料不均匀等因素,TOFD图像容易受到噪声干扰。同时,焊接材料自身的晶粒结构差异、化学成分变化等均会导致超声波传播特性不一致,进而产生背景噪声。上述特征导致基于TOFD图像的焊缝缺陷识别存在较大误差。
近年来,焊缝缺陷的自动识别技术成为研究热点[9],一些学者开始对融合深度学习的TOFD图像自动识别方法进行研究。Al-Ataby等[10]提出了一种基于纹理特征的TOFD焊缝缺陷图像检测方法,先利用二维Gabor函数对TOFD图像进行纹理特征分析,再利用模糊C均值聚类分类器对焊缝缺陷类型进行分类。林乃昌等[11]针对TOFD-D扫描图像中的焊缝缺陷,采用KPCA(kernel principal component analysis,核主元分析)算法提取特征,并利用微粒群优化算法自动优化核参数,最后使用支持向量机(support vector machine, SVM)完成缺陷分类。 Theresa Cenate等[12]从TOFD图像中手动提取待识别区域,计算均值和标准差等统计参数,并将其表示为图像特征,然后采用级联前馈反向传播(cascade feedforward back propagation, CFBP)网络对AISI316型不锈钢TOFD数据中的焊接缺陷进行了分类。综上,特征描述符可有效捕获特定缺陷的属性,如边缘[13]、轮廓[14]和纹理[15]等。然而,上述特征信息提取方法和分类器在处理大规模检测数据和复杂任务时,存在模型泛化能力差、智能化水平低等问题。
相较于传统的检测方法,基于CNN(convolutional neural network,卷积神经网络)的焊缝缺陷检测方法具有较强的学习能力和泛化能力,且在特征学习和图像结构理解方面表现优异。CNN通过卷积运算建立图像像素之间的密切联系,从而有效捕获特征图中的局部信息[16]。Roca Barceló等[17]通过设定小波阈值,应用小波变换技术消除了TOFD图像的噪声,并借助CNN实现了焊缝缺陷类型的精准分类。黄焕东等[18]分析了TOFD-D扫描图像中焊缝缺陷轮廓与图像特征之间的关系,并使用Faster R-CNN(faster region-based CNN,快速区域卷积神经网络)来检测和识别缺陷。针对图像去噪技术的局限性,支泽林等[19]提出了一种基于小波带特征融合的深度学习去噪模型,该模型通过特征提取、特征融合及图像重构,有效地实现了球形压力容器TOFD图像中的焊缝缺陷分类。但是,上述3种方法均需要在TOFD图像中预先截取缺陷区域。为解决这一问题,Zhi等[20]基于深度学习理论对Faster R-CNN模型进行了优化,提出了EFRCNN(enlighten Faster R-CNN,启发式快速区域卷积神经网络)框架,结合CF-RW(channel feature reweighting,通道特征二次加权)流程及基于ZSNF(Z-score normalization and fusion,Z分数标准化融合)的多尺度特征融合机制,实现了钛合金钢材TOFD-D缺陷图像的高效定位与识别。然而,CNN通常更擅长捕捉图像的局部特征,但焊缝缺陷图像往往包含复杂的结构特征和多样的缺陷形态,局部特征虽能够提供有用信息,但无法充分反映焊缝的整体特征和缺陷全貌。
现阶段,ViT(vision Transformer)模型及其众多变体[21-22]在图像领域快速发展,为焊缝缺陷检测提供了有力的技术支持[23]。作为Transformer的核心模块,自注意力机制通过计算查询(query)和键(key)之间的相似性来生成亲和矩阵,使其能够在整个图像上建立全局依赖关系,而不受卷积核大小的限制。然而,Transformer模型的特点是计算成本高、训练过程复杂及缺乏可解释性[24]。一方面,自注意力机制的计算具有二次复杂度和较高的内存消耗,这对复杂的实际工程应用提出了重大挑战;另一方面,计算所涉及的特征序列中的某些特征并不重要,这会导致不必要的计算开销。尽管ViT模型在缺陷检测领域展现出巨大的应用潜力,但其在局部特征提取方面落后于CNN,且需要大量的训练数据。
为应对上述问题,本文提出了一种名为MHLFNet(multi-scale high-low focused network,多尺度高低聚焦网络)的混合网络架构,该架构融合了CNN与Transformer模型的优势。通过设计多分支特征融合模块并引入映射函数与秩恢复模块,使得MHLFNet能够在有效降低计算复杂度的同时,针对性地解决TOFD焊缝缺陷图像特征信息易丢失的难题。
1 本文方法
1.1 MHLFNet整体架构
MHLFNet的整体架构如图1(a)所示,其能够有效融合多尺度信息,增强模型对目标细节和上下文的捕获能力。该网络主要包括Conv Block模块、Stage模块和分类模块。假设输入图像
图1
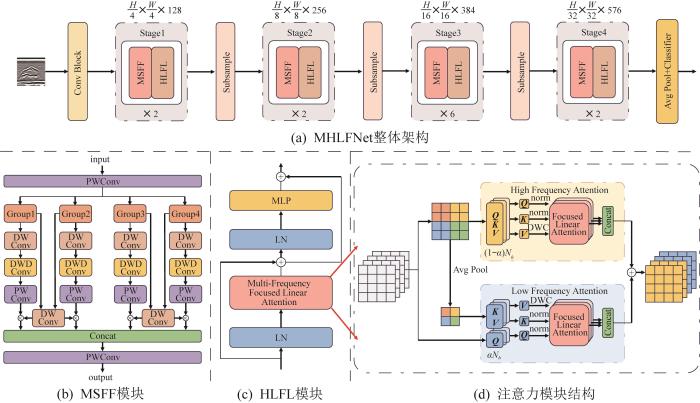
图1
MHLFNet整体架构及其关键模块
Fig.1
Overall architecture of MHLFNet and its key modules
1.2 MSFF模块
MSFF模块被集成到MHLFNet的各个阶段,其具体结构如图1(b)所示。该模块以多分支深度可分离卷积和空洞卷积为核心,通过分组策略高效提取多尺度特征,并结合权重自适应调整与特征融合机制,增强模型的表征能力。首先,MSFF模块通过逐点卷积(PWConv)将输入特征图的通道数扩展至原来的2倍,并在通道维度上进行分组,使每个分组专注于独立特征的提取。随后,每个分支依次执行以下3步操作:1)使用3×3卷积核的深度可分离卷积(DWConv)捕获局部细节特征;2)通过空洞率为2、卷积核为3×3的深度空洞卷积(DWDConv)来进一步扩展感受野,以更好地对全局上下文信息进行建模;3)通过逐点卷积调整通道数。上述操作用公式可表示为:
式中:
对于第
式中:F
最后,各分支的加权特征通过逐元素加和来实现内部融合,并通过逐点卷积进一步调整通道数至原始维度,进而完成特征的高效整合。综上,MSFF模块通过分组策略、深度可分离卷积和深度空洞卷积的结合,实现了高效的多尺度特征提取与融合。
1.3 HLFL模块
TOFD焊缝缺陷图像蕴含丰富的频率信息。其中:高频特征用于描述局部细节(如边缘与形状),低频特征用于描述全局结构(如纹理与颜色)。基于频率分解这一思想,本文提出了HLFL模块,即通过动态调节不同频段的特征权重,利用频段之间的互补作用,实现频率信息的有效融合,进而提升模型对复杂场景或缺陷的识别能力。HLFL模块的具体结构如图1(c)所示。
HLFL模块由3个关键层组成:归一化层(layer normalization, LN)、注意力层(attention)以及多层感知层(multi-layer perceptron, MLP)。具体而言,首先,输入特征通过第1个LN层和注意力层,生成注意力增强的输出;随后,利用残差连接将注意力增强的输出与原始输入相加,得到中间特征;最后,中间特征通过第2个LN层和MLP层进行进一步变换,并与中间特征通过残差连接相加,生成最终输出。以xA表示输入特征,则HLFL模块的整个计算过程可表示为:
式中:F表示HLFL模块的输出。
在注意力层中,对特征图的高频与低频信息进行独立处理,其详细结构如图1(d)所示。本质上,低频注意力分支聚焦于对输入特征的全局依赖关系进行建模,故对高分辨率特征的需求较低。而高频注意力分支聚焦于捕获输入特征局部细节的依赖关系,对高分辨率特征的需求较高,但仅需通过局部注意力即可完成建模。具体而言,引入分配比参数
Transformer模型主要依赖MHSA(multi-head self-attention,多头自注意力)来捕捉输入序列中远距离的关系。在编码器中,MHSA可以对输入序列进行全局的语义编码,使每个位置的编码都包含序列中其他位置的信息,从而较好地处理长距离的语义依赖。假设输入图像
式中:
在输入和输出具有相同维度的假设下,传统的MHSA可表示为:
式中:A表示注意力分数;d表示键的维度,
由此可得到MHSA的计算复杂度Ω:
上述MHSA的计算复杂度可表示为
首先,构造一个简单的映射函数
式中:
利用ReLU(rectified linear unit,修正线性单元)激活函数对特征
式中:
在常见的Transformer模型中[21],通道维度d通常小于标记数N,故可得线性注意力矩阵是一个降秩矩阵。而自注意力矩阵输出的是同一组值向量 V,注意力权重均匀化必然会导致特征之间具有相似性,这也是传统线性注意力特征矩阵多行相似的一个重要原因。为此,本文采用深度可分离卷积(DWConv)处理值向量 V,对应的输出O可表示为:
上述设计方法具有2个优点:第一,计算复杂度低,通过改变自注意力机制的矩阵乘法顺序,将计算复杂度降低为线性级;第二,模型表达能力强,使用聚焦函数和深度可分离卷积突破了模型的性能瓶颈,聚焦线性注意力机制的性能显著优于自注意力机制。
2 TOFD数据集构建和实验设置
2.1 TOFD数据集构建
图2
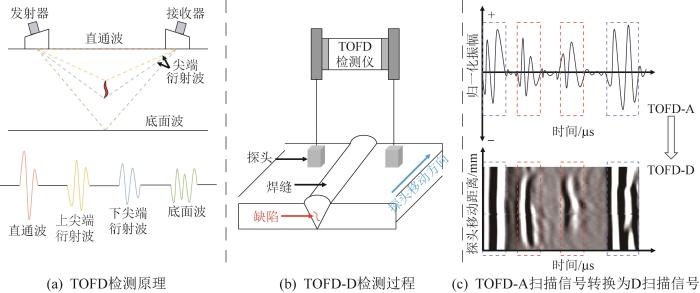
按照中国能源行业相关标准(NB/T 47013.10—2015)[27],制作了30块板-板对接的焊接缺陷试块,材质为Q235钢,规格为300 mm×300 mm,厚度分别为20、30、40 mm(各10块)。在焊接工艺上,选择手工电弧焊技术,坡口形状为V形,并在每块焊接试块的焊缝上设计3个缺陷,以满足测试需求。本文共设计了5种焊缝缺陷类型:裂纹、未熔合、气孔、夹渣和表面开口。按照表1所示的参数,选择规格合适的TOFD检测探头进行检测。TOFD焊缝缺陷图像如图3所示。由图3可以看出,不同类型缺陷的衍射回波特征存在显著差异:裂纹缺陷为尖锐、集中且信号强的衍射回波,与周围材料的衍射回波明显不同,但形状通常较为一致;气孔和夹渣缺陷多呈现散乱的衍射回波,分布较广泛,且信号较模糊、不连续;未熔合和表面开口缺陷表现为连续或层状的衍射回波,伴随结构变化明显,信号具有层状或平行特征。
表1 TOFD检测探头参数选择
Table 1
| 试块厚度/mm | 频率/MHz | 声束角度 | 晶片尺寸/mm |
|---|---|---|---|
| >15~35 | 5~10 | 60~70 | 2~6 |
| >35~50 | 3~5 | 60~70 | 3~6 |
图3

图4

表2 TOFD焊缝缺陷图像数据集划分
Table 2
| 数据集 | 缺陷图像/张 | ||||
|---|---|---|---|---|---|
| 裂纹 | 未熔合 | 气孔 | 夹渣 | 表面开口 | |
| 训练集 | 1 200 | 1 200 | 1 200 | 1 200 | 1 200 |
| 测试集 | 300 | 300 | 300 | 300 | 300 |
2.2 实验参数配置
本文实验基于PyCharm平台,采用深度学习框架PyTorch实现。硬件配置如下:NVIDIA GeForce RTX 3060 GPU(12 GB显存)和AMD EPYC 7R12 48核CPU(2.65 GHz)。MHLFNet模型的超参数如表3所示。在实验开始前,将图像分辨率统一调整至(224×224)像素,并对像素值进行归一化处理,将其范围映射至[0, 1],以加速模型收敛。
表3 MHLFNet模型的超参数设置
Table 3
| 参数类型 | 参数设置 |
|---|---|
| 优化算法 | AdamW |
| 损失函数 | 交叉熵函数 |
| 初始学习率 | 0.000 1 |
| 学习率调整策略 | 余弦退火,周期为30 |
| 批大小 | 32 |
| 迭代数/次 | 150 |
| 激活函数 | ReLU |
3 实验与结果讨论
3.1 模型分类性能验证
图5
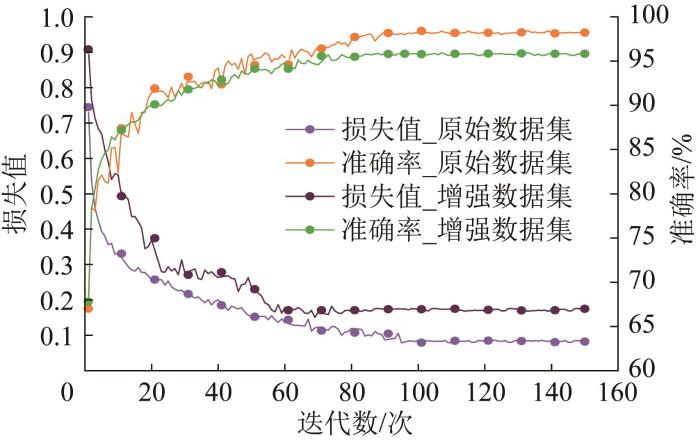
图5
MHLFNet模型的分类性能验证
Fig.5
Validation of classification performance of MHLFNet model
为深入评估模型的分类性能,还需重点关注模型对判别性特征的学习与区分能力。t-SNE(t-distributed stochastic neighbor embedding,t-分布随机邻域嵌入)作为一种高效的降维方法,能够将高维数据映射至二维空间,从而显著提升模型对数据的可视化分析能力。本文采用t-SNE对MHLFNet模型在增强数据集上的焊缝缺陷分类结果进行聚类分析,结果如图6所示。从图6中可以看出,不同的焊缝缺陷类别在特征空间中形成了清晰而独立的聚类,这充分验证了MHLFNet模型在识别和区分多种缺陷类型方面的优越性。同时,各类缺陷样本的分布呈现出高度紧凑性,进一步表明该模型在特征提取上的有效性。然而,裂缝与未熔合缺陷在语义特征上具有较高相似性,这种特征重叠不可避免地会导致模型存在一定程度的分类混淆和误判现象。
图6

3.2 消融实验
为了评估注意力机制对MHLFNet模型分类性能和计算复杂度的影响,设计了消融实验。保持网络其余结构不变,仅对基线网络中的注意力结构进行调整,实验结果如表4所示。通过分析可以发现,聚焦线性注意力机制在分类准确率和计算效率上均优于自注意力机制。这是因为自注意力机制需要计算所有输入元素的权重,导致计算复杂度呈平方级增长,而聚焦线性注意力机制仅需计算当前输入元素与少量相关元素的权重,可将计算复杂度有效降低至线性级。此外,无论是HLFL模块还是MSFF模块,均能显著提升MHLFNet模型的分类性能。尽管MSFF模块会略微增加模型的计算复杂度,但可使模型的整体计算开销得到优化。这一改进得益于模型结构的优化调整,具体表现为堆叠次数调整为2、2、6、2,且通道数由原先的512和1 024缩减至384和576。针对改进后计算量减少的现象,本文开展了进一步分析:优化后的网络通过在各层引入并行学习机制,融合了TOFD焊缝缺陷图像中的局部特征与全局特征。综上,MHLFNet模型通过串联和交替布局MSFF模块和HLFL模块,无需依赖过于庞大的结构即可充分提取和学习丰富的特征信息,从而在降低计算复杂度的同时显著提升分类效能。
表4 不同模块的消融实验结果
Table 4
| 基线网络 | MSFF模块 | HLFL模块 | 准确率/% | 损失值 | 参数量/106 个 | 浮点运算量/109 次 |
|---|---|---|---|---|---|---|
| √ | 96.1 | 0.375 | 28.00 | 3.7 | ||
| √ | √ | 97.6 | 0.217 | 28.84 | 5.3 | |
| √ | √ | 97.2 | 0.274 | 25.62 | 3.1 | |
| √ | √ | √ | 98.6 | 0.133 | 28.11 | 4.2 |
在聚焦线性注意力机制中,参数
图7
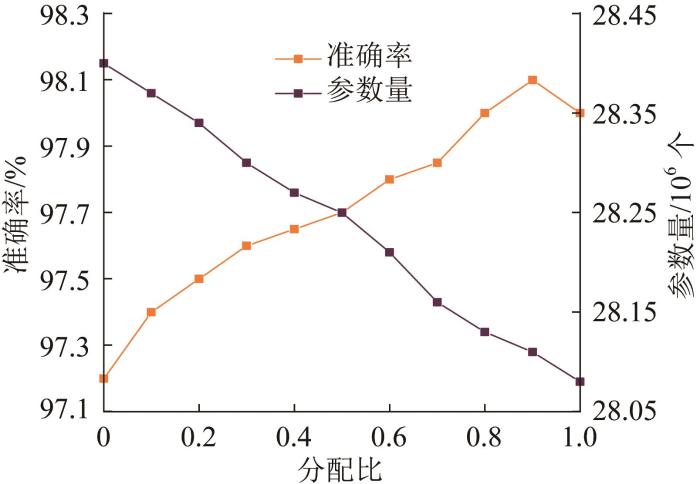
图7
分配比对MHLFNet模型性能的影响
Fig.7
Effect of allocation ratio on MHLFNet model performance
3.3 模型综合对比实验
为进一步验证MHLFNet模型的性能,选取几种典型的分类模型进行综合对比,各模型的分类准确率与计算性能参数的对比分别如图8(a)与图8(b)所示。从图8中不难发现,本文所提出的MHLFNet模型的分类准确率最高,达到了98.6%,这充分证明了其捕捉各类特征的卓越能力。值得注意的是,Transformer模型的分类性能普遍优于CNN模型,如Swin-Transformer(简称Swin-S)模型的分类准确率为96.1%,而ResNet34模型的分类准确率仅为93.5%。这一差距可归因于CNN过深的层次结构易导致梯度消失,进而削弱了网络的分类准确率。尽管ViT模型在精度上超越了CNN模型,但其高昂的参数量与浮点运算量是工程部署的重大阻碍。此外,ViT-Base模型因缺失局部信息提取能力,其分类准确率相较于MHLFNet模型下降了3个百分点。与传统CNN与Transformer的融合方法(如Swin-S模型)相比,MHLFNet模型不仅在分类精度上提升了2.5个百分点,而且在参数量上减少了91.1%,浮点运算量减少了85.9%,推理时间也缩短了69.1%。综上所述,可得以下结论:MHLFNet在大幅降低计算复杂度的同时,实现了识别精度的显著提升,验证了其高效性与实用性。
图8
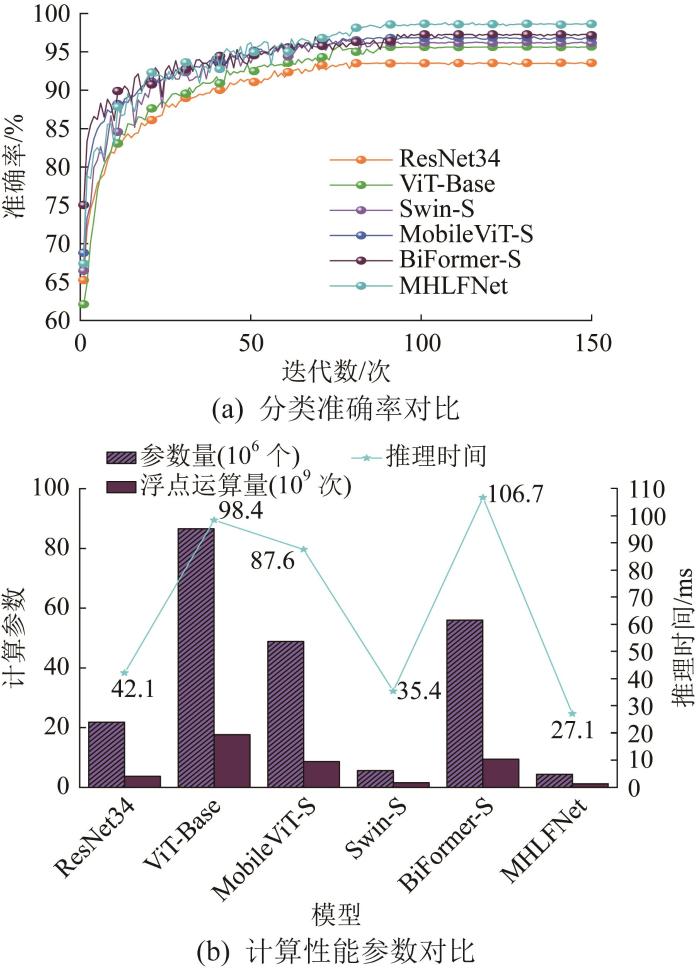
图8
不同模型的分类准确率和计算性能参数对比
Fig.8
Comparison of classification accuracy and computational performance parameters of different models
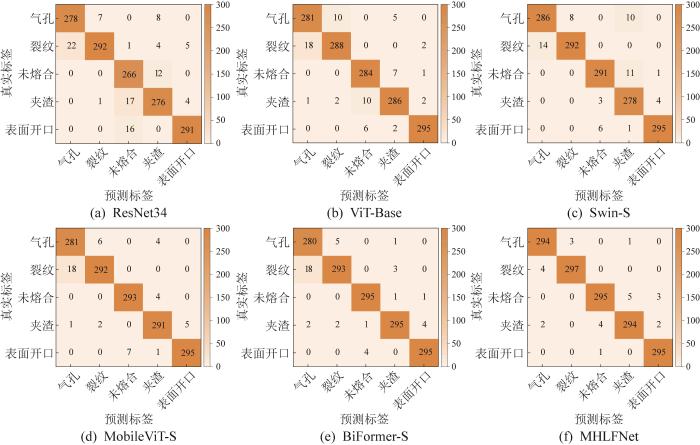
为直观呈现各模型对焊缝缺陷的分类效果,本文采用混淆矩阵对模型的分类性能进行量化分析,结果如图9所示。通过对比混淆矩阵可知,MHLFNet模型整体的识别精度最高,且不同缺陷类型的特征差异会对模型的识别精度产生显著影响。未熔合与裂纹在形态特征上存在显著差异(裂纹缺陷通常呈现细长且尖锐的形态,而未熔合缺陷的形状相对规则),这种鲜明的特征差异使得模型能够较为准确地区分这2种缺陷,从而实现了较高的识别精度。然而,气孔和夹渣在形态特征上具有一定的相似性,导致模型在识别这2种缺陷的过程中产生了一定程度的误识别,影响了模型整体的识别效果。此外,表面开口缺陷的衍射信号容易陷入检测死区,导致模型难以有效识别该类缺陷。
图9
3.4 可视化实验
图10

图10
MHLFNet模型的特征图可视化结果
Fig.10
Visualization results of feature maps of MHLFNet model
从特征图可视化结果可以看出,MHLFNet的Conv Block层主要捕捉缺陷的纹理、边缘等基础特征,充分体现了初始卷积运算在获取缺陷基本语义信息方面的强大能力。进入Stage1阶段后,MHLFNet对关键特征区域的关注度显著提升,这表明该模型在此阶段已具备初步构建全局特征映射的能力。在Stage2阶段,MHLFNet提取的纹理和边缘特征逐渐模糊化、抽象化,其所学习的特征信息包含更深层次的全局语义内容,这标志着全局特征建模能力显著增强。在Stage3阶段,特征图进一步抽象化,纹理和轮廓特征趋于模糊,表明模型开始关注更本质、更高层次的语义信息。作为最终特征提取层,Stage4层的输出为高度抽象的全局语义信息,更多关注全局特征分布的整体态势,而非具体的缺陷位置和类别。这一特性表明MHLFNet在特征提取的深层阶段已实现从细节到语义的抽象过渡,完成了对全局信息的整合。综上,MHLFNet模型在特征提取的浅层阶段主要聚焦于基础特征,而在深层阶段逐步过渡到对抽象语义和全局特征的提取。实验结果不仅验证了MHLFNet模型设计的科学性和合理性,也充分体现了其在提取局部与全局特征方面的卓越性能,为模型在复杂缺陷分类中的应用提供了强有力的理论支持。
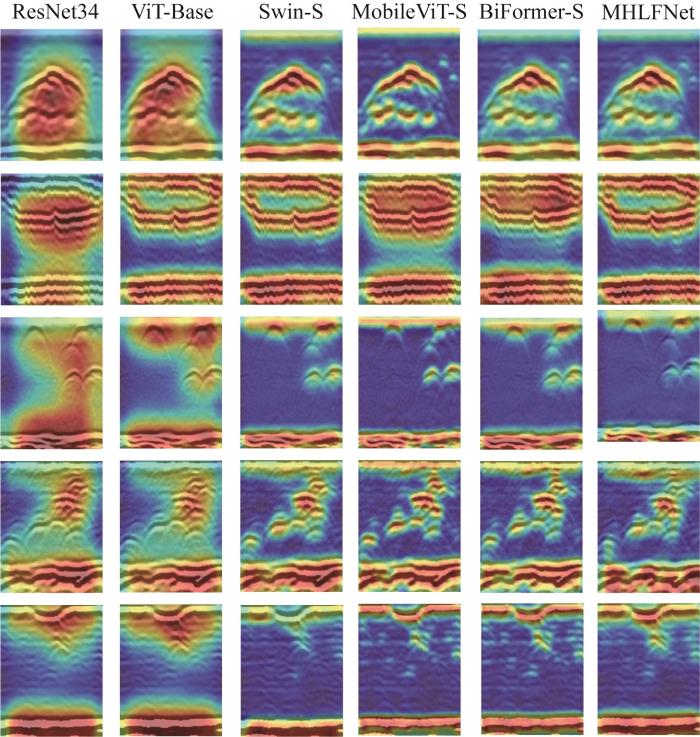
此外,深入理解深度学习模型所习得的判别性特征至关重要。为此,采用Grad-CAM(gradient-weighted class activation mapping,梯度加权类激活映射)技术[28]进行分析。该技术能够生成类别激活的热力图,从而直观地展示各模型在识别缺陷时的注意力分布情况。从数据集中挑选5类缺陷样本,利用Grad-CAM技术对各模型的识别结果进行可视化展示,结果如图11所示。图中:红色高亮区域为模型重点关注的区域。通过比较各模型在不同类别缺陷上的可视化结果,观察到 ResNet34模型较为宽泛地关注图像的语义信息,包括图像的上下端部区域,但在处理气孔缺陷时,其提取的特征出现了偏差。相较于ResNet34的热力图颜色略显单一和平面化,基于ViT-Base的热力图的色彩稍显丰富且立体感更强,这反映了2个模型在特征提取能力和表达能力上的差异。此外,Swin-S和MobileViT-S模型在整体轮廓信息的呈现上相对模糊。对此进行深入分析,可能的原因如下:1)Swin-S采用窗口滑动机制,虽能够高效地捕捉跨尺度的特征信息,但在捕捉整体轮廓方面存在不足;2)MobileViT-S作为轻量化模型,在计算量和参数量上受到限制,同时在特征融合方面存在缺陷,导致特征信息提取不充分。相比之下,BiFormer-S通过引入双层路由注意力机制,对传统自注意力机制进行了改进,但在分支间的信息交互方面仍有待提升。与MHLFNet模型相比,BiFormer-S模型对裂纹和未熔合缺陷的信息提取不足,增大了误判风险。
图11
4 结 论
本文系统地分析了传统CNN与Transformer模型在TOFD焊缝缺陷识别任务中的优缺点。针对基于ViT的焊缝缺陷识别方法性能不佳以及MHSA机制计算冗余的问题,提出了一种新型的混合分类网络——MHLFNet。该模型融合了CNN的局部特征提取能力和Transformer的全局建模优势,可有效提升分类性能并降低计算复杂度。为满足工程实验需求,设计并制作了包含多种缺陷类型的钢板焊接试块,采用不同规格的探头进行了TOFD检测,构建了焊缝缺陷图像数据集。随后,基于该数据集开展了相关实验,以验证MHLFNet模型的性能。实验结果表明,MHLFNet在捕获图像局部和全局特征信息方面表现优异,同时可有效降低计算复杂度。与目前最先进的分类模型相比,MHLFNet在参数量和浮点运算数方面具有显著优势,尤其在识别裂纹和未熔合等高风险缺陷时,该模型表现出更高的分类准确性。然而,MHLFNet的整体规模相对较大,且模型中设置的可调分配比将高/低频特征划分为固定比例,这样单一设置的阈值难以适应多样化场景,增加了参数调优的复杂度。未来工作将进一步探索参数动态调整机制,即根据输入图像的特征动态调整分配比等。
本文所提出的焊缝缺陷识别方法具有较强的适用性与扩展性,可推广至相控阵超声检测、射线检测等领域,展现出良好的实用价值与工程意义。未来研究可进一步验证该方法在其他领域识别任务中的通用性,以扩展其在多领域工业检测中的应用潜力。
参考文献
Deep learning-based welding image recognition: a comprehensive review
[J].
基于声信号识别的水下焊接质量检测方法研究
[J].
Research on detection method of underwater welding quality based on acoustic signal recognition
[J].DOI:10.3785/j.issn.1006-754X.2023.00.066 [本文引用: 1]
FMD-framework: a size estimation method for pipeline defects in weld-affected zones
[J].
An automatic deep segmentation network for pixel-level welding defect detection
[J].
高压电缆铝护套焊缝缺陷ACFM检测方法及检测系统的研究
[J].
Research on ACFM detection method and detection system for weld defects of aluminum sheath of high voltage cable
[J].
A state-of-the-art survey of welding radiographic image analysis: challenges, technologies and applications
[J].
不锈钢焊缝中超声传播特性及TOFD检测方法研究
[J].
Research on wave propagation characteristics in austenite stainless steel weld andultrasonic TOFD testing technique
[J].
Three dimensional characterization of defects by ultrasonic time-of-flight diffraction (ToFD) technique
[J].
Weld TOFD defect classification method based on multi-scale CNN and cascaded focused attention
[J].
Automatic detection and classification of weld flaws in TOFD data using wavelet transform and support vector machines
[J].
基于改进的KPCA的TOFD图像缺陷识别方法
[J].
Research on defect recognition of TOFD image based on improved KPCA
[J].
Optimization of the cascade feed forward back propagation network for defect classification in ultrasonic images
[J].
Detection for rail surface defects via partitioned edge feature
[J].
Contour extraction and quality inspection for inner structure of deep hole components
[J].
Automatic defect detection of texture surface with an efficient texture removal network
[J].
Deep CNN-based visual defect detection: survey of current literature
[J].
Development of an ultrasonic weld inspection system based on image processing and neural networks
[J].
基于区域的快速卷积神经网络的焊缝TOFD检测缺陷识别
[J].
Recognition of defect in TOFD image based on faster region convolutional neural networks
[J].
图谱数据深度学习融合模型及焊缝缺陷识别方法
[J].
A deep learning fusion model of wave and image data for weld defect recognition
[J].
An end-to-end welding defect detection approach based on titanium alloy time-of-flight diffraction images
[J].
Swin Transformer: hierarchical vision Transformer using shifted windows
[EB/OL]. (
BiFormer: vision Transformer with bi-level routing attention
[EB/OL]. (
Efficient Transformers: a survey
[J].
Vision Transformers in image restoration: a survey
[J].
Combiner: full attention Transformer with sparse computation cost
[EB/OL]. (
Paramixer: parameterizing mixing links in sparse factors works better than dot-product self-attention
[EB/OL]. (
Grad-CAM: visual explanations from deep networks via gradient-based localization
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}