



为满足日益严格的安全性需求, 代码审计和测试工作在软件研发中所占比重日益增大, 在大中型软件的研发中已达投入成本的六成以上[1].由于安全测试无法充分证明另一个程序的安全性, 代码审计工作无法完全脱离人工参与[2].针对人工审计所面临的耗时且易错的局限性, 目前主流方法是结合自动化分析方法, 通过对代码相关属性的分析来辅助人工分析, 从而减少分析的工作量, 提高分析效率和针对性.
数据流分析是一种典型的静态分析技术, 通过分析相关数据在程序执行路径上的传递情况计算分析对象的可能取值或性质, 判断程序状态是否违背程序的安全属性, 参数传递过程中的检查不完善是导致诸如注入、溢出等多类漏洞的主要诱因, 典型实例如“心血漏洞”和“破壳漏洞”等.Yamaguchi[3]将此类因数据流检查不完善所产生的漏洞定义为污点型漏洞(taint-style vulnerability).由于缺少真实的运行时信息, 数据流分析的精度主要受以下方面制约[4]:1) 如何精确提取代码的语法语义信息;2) 如何全面解析代码元素(如变量、函数、状态)间的关联关系;3) 建立模型分析前两方面的知识.
按照所关注的重点, 数据流分析可分为3类:流不敏感、流敏感和路径敏感分析.流不敏感仅按顺序分析各条语句, 精度较低;流敏感因结合了控制流信息使精度得到进一步提升;路径敏感在前两者基础上实现了对程序执行路径条件的判断.按照分析过程中所关注的范围, 数据流分析可分为过程内分析和过程间分析, 前者重点关注数据在同一函数内部的传递情况, 后者关注数据在若干函数间的传递情况[5].
面向C程序的数据流分析重点是识别代码中各变量间存在的多类依赖关系, 已有的研究中跟踪变量的状态、性质或取值往往通过代码建模实现, 典型的代码模型如三地址码[6]、状态自动机[7]等, 但这些模型因难以全面获取代码属性而影响了分析精度.针对代码属性信息不全面的问题, Yamaguchi等[8]将代码中各元素及其彼此间的各类关系以节点和边的形式展开分析, 提高了分析精度, 增加了能够静态识别的漏洞类型.
针对污点型漏洞检测, 本文提出了基于图模型的C程序数据流分析方法, 首先构建多维图模型, 将路径敏感的数据流分析转化为面向图模型的搜索过程, 通过过程内和过程间数据流分析求解安全相关变量可能的取值范围, 判断是否存在安全漏洞.实验结果表明本文所提方法能有效发现多种污点型漏洞, 同时有效降低了误报率, 并在VLC和Wine项目中发现了4个疑似漏洞.
1 相关工作本文关注的污点型漏洞是指因外界可控数据未经过充分检查而导致的漏洞, 常见的污点型漏洞有注入型漏洞、格式化字符串、权限认证漏洞等, 此类漏洞的产生一般具备以下共性条件:1) 外界可控的输入源(source), 本文将其统称为污点相关变量;2) 依赖source数据的安全敏感程序点(sink), 本文将参与sink点操作的变量称为安全相关变量;3) source到sink间存在可达路径并满足漏洞条件(unsanitary rule).
以“破壳漏洞”中导致远程代码执行的代码段为例进行阐述[9], 其中第14行语句对应产生漏洞的函数, 该函数将所传参数作为shell指令进行解析并执行.参数name由环境变量evn赋值, 外界可控, 且在传递至parse_and_execute函数过程中未进行完备检查.对该漏洞进行数据流分析过程中存在以下难点:首先需要判断temp_string和name是否外界可控, 包括其可能的取值范围;其次要推导经过一系列操作后, 到达parse_and_execute函数时的取值范围;对parse_and_execute函数做进一步分析, 判断该函数是否对参数进行过滤或检查.
/*bash/Variables.c*/
1 void initialize_shell_variables (env, privmode)
2 char **env;
3 int privmode; {
4 …
5 SHELL_VAR *temp_var;
6 /*从ENV环境变量中获取参数*/
7 for (string_index = 0; string = env [string_index++]; ) {
8 …
9 /*环境变量中异常字符解析并检查*/
10 strcpy (temp_string, name);
11 temp_string[char_index] = ″;
12 strcpy (temp_string + char_index + 1, string);
13 /*未检查参数的安全性即执行parse_and_execute */
14 parse_and_execute (temp_string, name, SEVAL_NONINT|SEVAL_NOHIST);
15 …
16 }//end for
17 }
静态分析通过提取程序的属性信息, 并依据控制流和数据流信息推断程序行为.在分析过程中将某程序点的解以集合形式展开, 通常基于格理论的偏序关系通过迭代实现对真实执行结果的逼近, 从而实现精确处理不同程序点所对应的解之间的关系.针对污点型漏洞展开的数据流分析, 主要关注到达脆弱点的数据属性, 通过求解满足漏洞条件的特定属性来实现.将程序内的关系属性转化为图的形式, 能够更方便地推导参数传递的偏序关系和变量定值操作的支配关系, 并以图搜索的方式定位满足特定模式的潜在漏洞.
2 数据流分析图模型 2.1 图模型构建为方便阐述, 首先对本文所提的相关概念进行如下定义.
定义1 (多维属性图G):本文所关注的代码属性包括结构信息、控制流信息、变量传递信息及函数调用信息, 程序代码P的属性信息可由有向图G表示, 各类属性信息在图G中以不同维的方式体现, 其中G可由四元组{Vk, Vk(P), Ek, Ek(p)}表示, 节点集Vk表示代码在k维度的节点元素, Vk(P)表示Vk在k维度的属性集, Ek表示代码在k维度中的关系所对应的边集, Ek(p)表示Ek所具备的属性集.
代码的结构信息由抽象语法树(AST)表征, 本文将属性图G的AST信息定义为第一维属性(k=1);控制流图(CFG)表征控制流信息, 并将相应信息定义为第二维(k=2);程序依赖图(PDG)表征变量间的直接依赖关系, 其信息对应第三维(k=3);函数调用图(FCG)对应第四维(k=4).不同维属性关注的对象不同, 从而实现不同粒度下的数据执行结果求精, 例如第四维(FCG)关注参数在函数间的传递情况, 第二维(CFG)关注变量在基本块间的处理过程.图G的各节点由属性和赋值表示相应信息, 各维度信息由边属性进行有区别的标记, 并通过图数据库进行存储和查询操作, 图G的构建过程整体描述如下:
1) 对代码P进行词法语法解析, 构建P的AST, 此时信息都定义为k=1维.
2) 在1) 结果基础上进行控制流分析, 并在AST中表示状态的节点间添加控制流边, 此时信息都定义为k=2维.
3) 在2) 的基础上分析当前函数内各节点的数据依赖和条件依赖关系, 添加相应的依赖边标记作为k=3维信息.
4) 在1)、2)、3) 基础上, 搜索各函数调用点的函数定义对应的AST根节点, 添加函数调用边及参数传递边作为k=4维信息.
为方便阐述, 现以如下所示的代码片段为例进行说明.该代码包含2个函数fun和sun, 若将sun (int x, int y)设定为sink点, 则需要计算参数x和y可能的取值范围.按照上述过程生成的多维属性图如图 1所示, 各函数和语句由相应抽象语法树表示, 不同维度的关系由不同属性的边进行标记, 在图 1示意图中以不同边表示.

|
图 1 多维属性图示意图 Fig. 1 Multidimensional property graph schematic |
1 int fun (int x){
2 int a = 2x;
3 int b = source ();
4 if (a<b)
5 sun (a, b);
6 else
7 sun (a, 1);
8 }
9 void sun (int x, int y){
10 printf (“value_add = %d\n”, x+y);
11}
在图 1中, 多维属性图总体上以语法树为基础, 每条语句还赋有状态属性, 如DECL和PRED分别表示变量声明和条件判断.CFG边表征状态间的依赖关系, 如∞表示任何条件下都会执行, true或false表示满足相应的PRED状态判断时执行, 其中定义ENTRY和EXIT状态表征函数的入口和出口边界.PDG边用来标记不同时刻各变量所依赖的前置状态, FCG边建立了函数调用点与函数体间的对应关系.
定义2 (变量定值图D)在多维属性图G基础上, 对于给定的某程序点的变量r, 定值图D={V, E}表征与r定值相关的信息, 其中v(v∈V)对应G中影响r定值结果的状态节点, e(e∈E)表示G中对r定值状态的转化关系, 包括调用关系、参数赋值关系、控制流关系等.
将各程序点处所有变量的取值属性定义为相应的程序状态s, 且将In [s]和Out [s]分别表示该状态点执行前后数据流的取值集合, 如s1和s2是连续执行的2个状态, 则存在关系Out [s1]= In [s2].定义s所对应的语句为状态转换函数fs, 表示该语句对程序状态的影响, 其中fs满足Out[s]=fs(In[s]), 由于fs可能引入新的变量定义gen [s]或消除已有的变量kill [s], fs也可以用fs=(In [s]-kill [s])∪gen [s]的形式表征.程序的执行可视为各状态间的转换过程, 因此抽象数据流分析可具体化为程序状态序列s0, s1, …, sn和对应转换函数序列fs0, fs1, …, fsn所表征的程序流路径.假设s0和sn分别是关注的数据流起止点, 则该执行路径的起止状态可由式(1) 表示[10]:
| $ {\text{In}}[{s_n}] = {F_s}(Out[{s_0}]), {F_s} = {f_{{s_0}}} \oplus {f_{{s_1}}} \oplus \ldots \oplus {f_{{s_n}}}. $ | (1) |
该公式适用于G中不同维度的分析, 如CFG维以基本块B为单位定义转换函数fB, 则起始块B0至终止块Bn间仍满足In [Bn]=Fs(Out [B0]), FB=fB0⊕fB1⊕…⊕fBn.
变量r从source点传递至sink点过程中会经过若干定值操作和条件判断, 依据式(1) 对参与sink点操作的变量r进行定值分析, 得到r的定值域D, 假设程序在sink点正常执行时r需要满足的安全取值域为S, 则只需判断到达sink的条件约束P满足D∩P∩(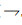
定义3 (条件支配树T)条件支配树T用于表征source点到sink点必定经过的判断状态, 其根节点是sink点, 叶子节点是所有相关的source点, 中间节点为数据流路径上必经的判断操作或定值操作.分别以图 2中sun (a, b)和sun (a, 1) 两点为例, 其对应的条件支配树分别如图 2所示.

|
图 2 sun(a, b)和sun(a, 1) 对应的条件支配树 Fig. 2 Condition dominator trees for sun(a, b)and sun(a, 1) respectively |
跟踪程序的所有状态并不现实, 往往需要忽略不关注的细节, 本文过程内分析仅关注参与sink点安全相关变量的定值分析, 此外还包括与之相关的局部变量和全局变量的定值分析.依据PDG边的标记信息, 实现待分析状态节点的具体选择算法如下:
for v in current-function:
v.label←false
label_dependent _data (v):
v.label←true
foreach u in edge_PDG(v):
label_dependent _data (u)
选择与sink点数据依赖相关节点的算法核心是从sink点开始, 沿PDG边逆向标记其数据依赖的前置节点, 以此迭代完成对当前函数内的所有相关节点的标记.
根据执行路径上相邻语句是否顺序执行, 将程序的执行划分为各基本块, 在基本块内部, 前一条语句之后的程序状态和下一条语句之前的程序状态相等.例如连续执行的基本块B1和B2, B1中最后一条语句之后的程序状态与B2中第一条语句之前的状态等价.为减小分析范围, 本文在跟踪数据传递时只分析含有算法1标记节点的基本块, 该过程主要包括基本块划分和关注块的标记, 具体实现如下所示.
procedure patition_basic_block(Func):
v[0…n] in Func
B[].start, B[].end, B[].label←NULL
//store basic block info
B[0].start←v[0], j←0
for (i:0, n-1):
if v[i].label=true: B[j].label←true
if edge_CFG(v[i], v[i+1])!=∞
B[j].end←v[i]
B[j++].start←v[i+1]
return B[]
对于该标记算法, 有些控制流路径上可能存在不关注的基本块, 由于未标记的基本块不影响污点相关变量的定值结果, 所以在相关变量定值分析过程中, 只需考虑控制流路径上关注基本块间的拓扑顺序即可.拓扑顺序的确定对于变量的定值结果至关重要, 但依据控制流信息仅能推断可能的后继状态.因此, 与定义3的支配方向相反, 由CFG和PDG构建到达目标节点的反向条件支配树, 得到的用于表征状态间的执行顺序, 如节点n支配节点d, 表示的是到达n状态前必先经过d.
首先依据每条语句对应的AST子树得到对应的转换函数fs, 基于公式(1) 进一步推导基本块对应的转换函数fB, 从而实现以块为单位的定值分析.对于同一程序点, 沿不同的路径往往会求解得到不同的结果, 因此定值分析应与CFG维的控制流路径建立对应关系, 体现不同条件下的数据流分析结果, 本文用value (l, r)来表示r在路径l上对应的定值结果.依据变量的定值操作是否只有常量参与, 分为常量定值和非常量定值, 其中常量定值分以下2种情况:
1) 若变量r在某处被定值为常量, 且在到达sink点过程中没有再被定值, 则r到达sink的定值结果为该常量;
2) 若变量r在不同路径上被定值为不同常量, 依据定值结果划分等价路径集, 将各路径集的到达定值结果取相应的常量.
对于非常量定值情况, 为建立关注变量的数据流值(data-flow value)与各程序点的对应关系, 以定值域(define domain)的形式表征该程序点所有可能的取值范围.为表示不同程序状态点的定值域, 本文提出了必然域(certain_domain)和可能域(possible_domain)分别表示保守分析的结果和完备分析的结果, 其中必然域指能够确定的定值范围, 往往是指定路径的定值域的交集;可能域指所有可能到达的定值范围, 往往是指定路径的定值域的并集.在变量的定值图中, 有些变量的取值域未知, 必然域和可能域分别遵守定值分析的保守原则和充分原则, 前者仅给出能够确定的定值结果, 后者将所有哑定值、外界可控数据等值域设为其长度对应的全体域.如图 2所示代码中, 若将fun (int x)中x的初始取值域设为[-215, 215), 则a的取值域为[-216, 216).对于间接依赖的情况, 按照充分原则, 若依赖变量污点相关, 则将赋值变量取值域按污点变量取为全体域.关于定值域的求解基于文献[11]所用方法, 以区间代数的形式表示各变量的取值范围.
为实现对变量间指向关系和层次关系的分析, 为内存对象赋左值属性来表示其地址, 将‘ & ’、‘*’、‘[]’等符号参与的操作表征指向关系, 将‘→’、‘.’等符号参与的操作表征层次关系, 其中指向关系往往是一个变量左值与另一变量右值间的关联, 层次关系是变量左值间的关联, 对形如*ptr[i]→r的复合关系, 则需先分解后展开分析.在文献[11]所提符号化三值逻辑RSTVL的基础上, 本文重点关注是否存在空指针引用和指向非法区域问题, 将内存对象分为指针pointer_r、数组arry_r和类class_r, 定义左值为null表示空指针, wild表示为野指针[12].
基于多维属性图标记内存对象, 以RSTVL区域描述其可寻址表达式, 进而判断指针变量是否存在潜在漏洞.建立变量间的指向关系还有效避免了别名分析、参数引用等问题, 为过程间数据流分析提供了关联依据.
2.3 过程间分析污点相关变量沿数据流路径传递过程中往往会跨多个函数, 如果仅按2.2所述的过程内分析难以实现完整的数据流跟踪求解, 尤其当被调函数影响安全相关变量的定值结果时, 过程间分析能够得到更准确的执行结果.依据程序中是否包含被调函数代码, 本文分别对库函数和自定义函数的过程间分析展开讨论.
C程序中常存在被调函数为库函数或共享函数的情况, 本文将此类无法获取函数代码的函数统称为库函数, 调用库函数对变量定值的影响可以分为2种情况:以函数返回赋值的方式(a=abs (x)), 以参数传递的方式(如strcat (str1, str2)).对于前一种情况, 本文对其进行标注, 默认将无参数的库函数(如getchar ())作为输入源, 并将所赋值的变量定值域设为全体域(变量对应长度下的0…00~1…11);将有参数的库函数(如sin (double x))以注释的形式赋值定值域, 如-1≤sin (x)≤1、abs (x)≥0等.对于后一种情况, 由于无法通过库函数的特征判断对所传参数的定值是否有影响, 例如fread和fwrite函数的第1个参数都是指针变量, 但难以判断其是否对该指针所指内存区域产生影响.针对该问题, 本文采用基于统计的启发式策略进行判断[13], 整体思路是统计库函数的调用满足一定比例时才将其视为影响该参数的定值.为减少对库函数误用的漏报, 本文选取较低的阈值ρ=20%.判断的具体步骤描述如下:
Step1:统计所有库函数的调用点, 筛选以参数传递调用的库函数, 以函数名为索引统计各函数的调用次数{ni};
Step2:对各个库函数的参数进行如下检查:1) 局部变量是否作为库函数的实参, 2) 局部变量从声明点到达调用点的路径中是否被赋值;
Step3:统计各函数满足step2中2个条件的调用次数{mi}, 计算各库函数符合影响参数定值条件的比例{mi/ni};
Step4:当库函数mi/ni≥ρ时, 则将该库函数标记为对参数定值.
上述方法可实现对库函数的定值分析.有时数据流路径会涉及多个自定义函数, 为推导跨函数变量的定值域, 需要跟进被调函数内部进行分析.围绕该问题, 本节通过结合多维属性图中的FCG维信息, 当变量以参数赋值或返回赋值形式产生定值时, 对多维属性图进行类似于系统依赖图[14](system dependence graph)的扩展, 一方面引入调用点作为实参的变量指向被调函数形参的数据依赖边, 一方面引入调用点指向被调函数ENTRY点的边和EXIT点指向调用点的边.若函数调用以参数传递, 建立形参到实参的数据依赖边, 若以引用传递, 则通过赋左值属性建立形参到实参的指向关联.
以图 2示例代码的sun (a, 1) 为例, 进行过程间扩展后的多维属性如图 3所示.

|
图 3 过程间分析的多维属性图扩展 Fig. 3 Multidimensional property graph expansion for interprocedural analysis |
建立过程间的数据依赖关系和控制流关系后, 结合FCG维的函数调用关系建立函数调用链L, 进而确定数据流路径上的各函数间拓扑关系.将过程间的数据流传递信息纳入考虑后, 沿调用链L再分别对各函数展开过程内分析, 最终实现对污点相关变量的过程间定值分析, 具体算法描述如下所示:
procedure fun_call_chain (v4):
for v in v4.out (e4):
if v is lib_func:// mark annocation
annocation_lable(v)
else://add edges for function call
add_edge(e2, vf.CallExpression.Callee, v.ENTRY)
add_edge(e2, v.EXIT, vf.CallExpression.Callee)
add_edge(e3, v.argument, v4.parameter)
fun_call_chain (v)
procedure interprocedural_analysis()
for vf along fun_call_chain:
inprocedural_analysis(vf)
2.4 定值图构建在过程内和过程间的分析方法基础上, 当确定source源到sink点的流路径后, 即可求解到达sink点的安全相关变量的定值结果, 因此确定数据流路径的起止点是进一步分析的前提.指定sink点后, 参与安全敏感操作的参数或变量, 往往难以直接获取影响其定值结果的数据源, 本文通过构建定值图, 求解到达sink点各变量的定值结果及安全检查范围, 主要分以下2部分:
1) 以sink点为起点, 寻找所有影响安全相关变量定值结果的前置状态, 迭代搜索, 直至外界输入源或变量初始化处为止, 将溯源的终点作为source点.
2) 沿定值图的PDG边对定值域D进行求导, 同时收集CFG路径上的安全检查条件P, 当到达sink点时安全相关变量可能的取值范围D∩P和安全敏感操作所允许的范围S间的关系.
基于扩展的多维属性图, 沿数据依赖边和控制流边逆向回溯, 可以得到各安全相关变量的数据源.对于循环结构的代码, 首先将其解析为抽象语法树形式, 再添加其他维的边, 由于数据间的依赖关系和支配关系是偏序关系, 构建定值图时能够有效避免循环陷入问题.为缓解定值图构建过程中的路径爆炸问题, 本文对支配节点中存在常量或必然域的路径进行忽略处理, 实际测试中该方法可以约减大部分污点无关路径.
基于代码切片分析可以得到污点相关变量到安全相关变量间的定值图[15], 为缓解定值分析面临的过度定值的问题, 本文采取的解决方法是对其进行进一步分解, 将定值操作与控制流路径对应, 最终形如一棵以sink为根节点的倒树, 分解后得到的定值图如图 4所示.

|
图 4 以sun()函数为sink点的定值图 Fig. 4 Definition graph taking sun() as sink point |
假设fun (int x)的x和source()都是外界可控源, 则其取值域都可设为[-215, 215), 按原来的定值图, 到达sink点处的x和y的取值域将分别是[-216, 216)和[-215, 215), 但由于调用点sun(a, 1) 的参数y被赋值为1, 使得对x和y的定值结果与虚线对应的数据流路径产生分歧.由此可见, 将各安全相关变量的定值结果进行简单的并集操作, 无法准确刻画不同路径的执行结果, 定值分析的结果应与控制流流路径进行对应, 以图 4为例, 实线路径到达sink点的定值结果为x:[-216, 216)和y:[-215, 215), 虚线路径对应的定值结果为x:[-216, 216)和y:1.
此时得到的定值结果仅为可能域, 例如虚线路径的定值结果依赖的条件是a<b且a为int型, 由于b的最大取值为215-1, 所以x值域应是[-215, 215), 但由于y被赋值为常量1, 故其值域属于必然域.变量定值的必然域一般能保证程序的正确执行, 本文重点检查各路径的可能域是否完备[16].因此, 可认为图 4中虚线路径为“安全的”, 当满足a+b≥215条件时实线路径的执行结果产生整数溢出.
3 实验及结果分析 3.1 漏洞检测为验证本文所提方法的有效性, 对代码分析工具Joern进行扩展和二次开发, 在原有基础上添加的icfg.jar模块实现对过程间分析的图扩展, 基于前述图模型构建和定值分析算法, 实现了针对污点型漏洞的检测工具DataFlow-checker.该工具主要由3个模块构成:ANTLR完成对目标代码的词法语法解析, Joern++完成多维属性图的构建和过程间分析的扩展, Traversal通过对图进行遍历操作完成安全相关变量的定值分析和漏洞判断.整个检测工具运行在Linux系统上, 其中图数据库采用Neo4j, 为满足中等规模以上的代码分析, 属性图的存储和查询需要较大的本地存储和内存空间, DataFlow-checker完成漏洞检测的主要流程如图 5所示.
|
|
图 5 DataFlow-checker检测的主要步骤 Fig. 5 Main steps of DataFlow-checker |
在整个检测过程中, 漏洞的判断依赖定值域和安全约束, 前者得到sink点处安全相关变量可能的
定值域D, 后者将传递过程中的所有安全约束条件P纳入考虑, 对定值域做进一步修正, 最终比较到达sink点的可能域D∩P与安全域S间的包含关系, 若D∩P∩(
本文以公开的测试集Juliet Test Suite作为测试对象, 该测试集由近十万个C/C++示例代码组成, 涵盖了118类典型漏洞, 每个样例代码中都由含有漏洞和修复后的函数组成.通过统计实际漏洞总数(numt)、检测报告中的漏洞数(numr)和命中漏洞数(numh), 测试效果由覆盖率(RC)和误报率(RFN)来衡量:
| $ {R_{\text{C}}} = \frac{{{\text{nu}}{{\text{m}}_{\text{h}}}}}{{{\text{nu}}{{\text{m}}_{\text{t}}}}}. $ | (2) |
| $ {R_{{\text{FN}}}} = \frac{{{\text{nu}}{{\text{m}}_{\text{r}}} - {\text{nu}}{{\text{m}}_{\text{h}}}}}{{{\text{nu}}{{\text{m}}_{\text{r}}}}}. $ | (3) |
实验从Juliet Test Suite中选取了4类典型的污点型漏洞来进行测试:堆溢出、格式化字符串、整数溢出和除零错误.和当前较为流行的代码测试工具在同一测试集上的检测结果进行对比, 检测覆盖率和误报率结果如图 6和7所示.

|
图 6 代码检测工具间的检测覆盖率对比图 Fig. 6 Coverage contrasts among code detecting tools |

|
图 7 代码检测工具间的检测误报率对比图 Fig. 7 7 Contrasts on false positive rate among code detecting tools |
从上述对比测试结果可以看出, 静态分析工具测试效果很大程度依赖于检测规则, 如CPPCHECK虽可以检测出大多printf参数不匹配, 却难以发现算数运算相关的漏洞;高覆盖率往往伴随高误报率, 如flawfinder在堆溢出测试集合中将所有mem*操作都标记为潜在的漏洞点, 虽然覆盖率较高, 但也把修正后的代码视为疑似漏洞, 造成大量误报.与其他工具的检测原理相似, 对于不同类型的漏洞, DataFlow-checker都需要定制相应的检测规则, 如针对堆溢出测试集, 首先将所有*alloc和mem*语句都作为sink点, 进而溯源到外界可控的source点, 并推导sink点参数的定值域.例如memcpy产生溢出的一种典型情况, 由malloc函数分配的空间与memcpy函数所拷贝的空间都由算数表达式来定值, 且两者定值域不一致时即可认为存在漏洞, 因此检测该漏洞的搜索规则可描述为如下:
getCallsTo(“malloc”).ithArguments(“0”).sideEffect{cnt=it.code}.match{it.type
通过对漏报代码和误报结果的分析, DataFlow-checker产生漏报的主要原因是无法自动将自定义函数设定为sink点, 如CWE122_Heap_Based_Buffer_Overflow cpp_CWE805_wchar_t_ncpy_01编号代码的漏洞在于自定义的wcsncpy()函数;DataFlow-checker产生误报的主要原因是把导致同一漏洞的多处操作分别进行了提交, 如上述的规则会检测堆溢出的同时也检测出整数溢出, 造成一个测试例代码存在多处漏洞的情况.与传统的规则匹配和危险函数标记的静态检测方法相比, DataFlow-checker综合代码的多维属性对关注的程序点进行定值分析, 有效降低了误报率, 由于其检测效果依赖指定的sink点和source数据的取值域, 所以进一步降低其漏报率仍需要优化相应的检测规则.
为检测DataFlow-checker的检测效率, 选取了代码规模不等的开源项目进行对比实验, 并与其他工具进行对比.从总体上看, 对同等规模的测试目标, DataFlow-checker和Fotify所耗时间在同一量级, CPPCHECK和flawfinder的测试效率比前两者高一个量级.将分析过程总体分为多维属性图构建所用时间和图搜索所用时间2部分, 对比结果如图 8所示.分析对比的结果, 在同等实验环境下, DataFlow-checker所耗时间随代码规模的增长呈指数递增, 其中多维图的构建占近90%的时间.

|
图 8 DataFlow-checker在不同规模代码上的时间对比 Fig. 8 Contrasts on time spent for different projects with DataFlow-checker |
| 表 1 DataFlow-checker检测的实际项目列表 Table 1 List of practical projects checked by DataFlow-checker |
通过对若干开源软件进行测试, 验证了5个已公开的污点型漏洞, 并在VLC播放器和wine代码中发现了4个疑似漏洞, 通过向开发商提交相关信息, 其中部分疑似漏洞得到了开发商认可和修复, 如在新公布的VLC-2.2.4和wine-1.9.10版本中, 厂商对相应代码添加了对内存越界的检查.
4 结语本文提出一种基于图模型的C程序数据流分析方法.针对数据流分析面临高误报的问题, 围绕污点型漏洞的常见成因, 构建了多维属性图模型.将传统的面向代码的数据流分析转化为面向图的分析, 并在此基础上定义了变量定值图和状态支配树的概念.依据分析的范围是否跨多个函数, 分别设计了过程内分析和过程间分析的相关算法, 结合区间代数的相关运算规则, 最终通过构建定值图的形式推导不同流路径下的定值域.依据sink点正常执行的安全域S与可能的定值域D∩P间的包含关系, 判断是否存在潜在漏洞.在构建的图模型基础上, 针对不同类型的漏洞制定相应的搜索规则, 并对公开测试集和开源项目进行验证测试.结果表明本文所提的方法具有较强的可操作性, 尤其在指定sink点的情况下, 能够达到较好的效果, 大大降低了传统数据流分析所产生的误报率, 为更好地检测污点型漏洞提供了新的思路和方法.
本文的局限性主要体现在减少漏报上, 一方面尽可能多地覆盖可能存在漏洞的sink点, 一方面制定更完备的搜索语句, 这些工作仍需依赖人工分析完成.如何根据待分析代码的特征预判可能的漏洞类型, 并自动构造搜索规则将大大减少人工参与分析的工作量, 这是未来要改进的工作.
| [1] | WANG R, FENG D G, YANG Y, et al. Semantics-based malware behavior signature extraction and detection method[J]. Journal of Software, 2012(2): 378–393. |
| [2] |
李舟军, 张俊贤, 廖湘科, 等. 软件安全漏洞检测技术[J].
计算机学报, 2015, 38(4): 717–732.
LI Zhou-jun, ZHANG Jun-xian, LIAO Xiang-ke, et al. Survey of software vulnerability detection techniques[J]. Chinese Journal of Computers, 2015, 38(4): 717–732. |
| [3] | YAMAGUCHI F, MAIER A, GASCON H, et al. Automatic inference of search patterns for taint-style vulnerabilities [C]// Ecurity and Privacy. San Jose, California: IEEE, 2015: 797-812. |
| [4] | DAHSE J, HOLZ T. Simulation of Built-in PHP features for precise static code analysis [C]//Network and Distributed System Security Symposium, San Diego, California : DNSS, 2014: 23-26. |
| [5] |
万志远, 周波. 基于静态信息流跟踪的输入验证漏洞检测方法[J].
浙江大学学报:工学版, 2015(4): 683–691.
WAN Zhi-yuan, ZHOU Bo. Static information flow tracking based approach to detect input validation vulnerabilities[J]. Journal of Zhejiang University :Engineering Science, 2015(4): 683–691. |
| [6] | NECULA G C, MCPEAK S, RAHUL S P, et al. CIL: Intermediate language and tools for analysis and transformation of C programs[C]// Compiler Construction. Grenoble, France: IEEE, 2002: 213-228. |
| [7] | CORBETT J C, DWYER M B, HATCLIFF J, et al. Bandera: Extracting finite-state models from Java source code[C]// Software Engineering. Buenos Aires, Argentina: IEEE, 2000: 439-448. |
| [8] | YAMAGUCHI F, GOLDE N, ARP D, et al. Modeling and discovering vulnerabilities with code property graphs[C]//Security and Privacy. San Diego, California: IEEE, 2014: 590-604. |
| [9] | GNU Bash shellshock remote code execution vulnerability report[EB/OL]. [2014-09-09]. http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-6271 |
| [10] | AHOA V, 阿霍, SETHIR, 等. 编译原理[M]. 第2版. 北京: 机械工业出版社, 2012: 382-393. |
| [11] |
王雅文, 宫云战, 肖庆, 等. 基于抽象解释的变量值范围分析及应用[J].
电子学报, 2011(2): 296–303.
WANG Ya-wen, GONG Yun-zhan, XIAO Qing, et al. A method of variable range analysis based on abstract interpretation and its applications[J]. Acta Electronica Sinica, 2011(2): 296–303. |
| [12] |
万志远, 周波. 支持局部调用图生成的指针分析[J].
浙江大学学报:工学版, 2015(6): 1031–1040.
WAN Zhi-yuan, ZHOU Bo. Points-to analysis for partial call graph construction[J]. Journal of Zhejiang University :Engineering Science, 2015(6): 1031–1040. |
| [13] |
董玉坤, 宫云战, 金大海. 基于区域内存模型的空指针引用缺陷检测[J].
电子学报, 2014, 42(9): 1744–1752.
DONF Yu-kun, GONG Yun-zhan, JIN Da-hai. Null pointer dereference defect detected based on region-based memory model[J]. Acta Electronica Sinica, 2014, 42(9): 1744–1752. |
| [14] | HORWITZ S, REPS T, BINKLEY D. Interprocedural slicing using dependence graphs[J]. Transactions on Programming Languages and Systems, 1990, 12(1): 26–60. DOI:10.1145/77606.77608 |
| [15] |
张迎周, 符炜. 一种过程间单子切片方法[J].
电子学报, 2013(8): 1457–1461.
ZHANG Ying-zhou, FU Wei. An approach of monadic slicing for interprocedural programs[J]. Acta Electronica Sinica, 2013(8): 1457–1461. |
| [16] | GODEFROID P, LEVIN M Y, MOLNAR D. SAGE: whitebox fuzzing for security testing[J]. Queue, 2012, 10(1): 20. DOI:10.1145/2090147 |