两方零和马尔科夫博弈策略梯度算法及收敛性分析
Policy gradient algorithm and its convergence analysis for two-player zero-sum Markov games
两方零和马尔科夫博弈策略梯度算法及收敛性分析 |
| 王卓,李永强,冯宇,冯远静 |
|
Policy gradient algorithm and its convergence analysis for two-player zero-sum Markov games |
| Zhuo WANG,Yongqiang LI,Yu FENG,Yuanjing FENG |
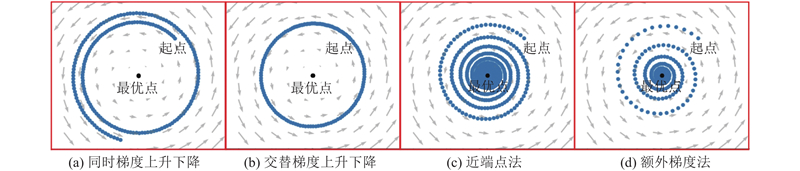
| 图 1 不同更新规则的探索轨迹 |
| Fig.1 Exploration trajectories for different update rules |
|
|