



利用现有组件与代码模板进行开发已经成为软件工程中的常用手段,现有研究指出知名代码仓库GitHub中70%的代码由以前创建文件的克隆组成[1]. 开源代码作为提高开发效率、降低开发成本的良好选择,在互联网应用、网络安全、医疗卫生、大数据与人工智能、工业控制与自动化等领域有着广泛应用. 引用开源项目、调用第三方库以及使用公开组件等手段使得开源代码从不同渠道进入到各类项目中,含有漏洞的代码(脆弱性代码)也被同时引入. 开源项目的漏洞信息通常会通过漏洞数据库、邮件列表和项目主页等公开渠道披露,获取漏洞细节的门槛较低,项目受到攻击的风险较高. Black Duck公司在《开源软件安全与威胁分析报告》[2]中指出,超过67%的使用开源组件的商用软件中存在已知的漏洞代码;Korolov[3]估计2017年基于开源代码漏洞的攻击总量比上年增加20%. 研究开源项目中脆弱性代码复用的检测方法对保证信息安全具有重要意义.
脆弱性代码的复用是引发漏洞的重要原因之一,检测脆弱性代码复用是面向源代码进行漏洞挖掘的重要手段之一. 代码克隆是代码复用的基本手段,Jones[4]指出代码复用的手段通常是在代码克隆的基础上使用修改注释、重命名、更改操作符或操作数、调整语句顺序、更改代码块顺序、添加冗余代码、更改数据类型、控制结构的等价变换. 目前Roy等[5]提出的对代码克隆过程中的修改操作的分类方法受到了普遍认可. Level1修改是指仅重新排版和删改注释,不对代码部分进行任何变动;Level2修改是指对函数名、变量名等标识符进行重命名,并改变变量、函数返回值的数据类型;Level3修改是指在不影响正常功能的前提下,添加或删除少量语句,替换部分表达式或函数调用;Level4修改是指在不影响语义的前提下调整代码结构,更改代码顺序,进行控制结构的等价变换. 包含Level2、3、4中的修改手段的克隆通常被称为近似克隆(near-miss clone),也被称为代码复用. 随着代码修改程度的不断增加,代码复用检测的难度也不断增大. 现有工作可以准确完成对Level1、2修改手段的检测,但是更进一步的检测需要在分析结构、语义的基础上利用中间表示完成,计算开销较大. 常见的代码克隆通常包含Level3、4的修改,高效检测包含此类修改的脆弱性代码复用意义重大.
Jang等[6]提出快速查找操作系统代码库中脆弱代码克隆的工具ReDeBug. ReDeBug以代码行为检测粒度,使用面向Token流的滑动窗口算法与Bloom filter查找脆弱性代码的克隆. ReDeBug支持面向大规模代码库的检测,具有检测效率高的优势,但是无法应对变量重命名或数据类型更改等常见代码修改手段,存在较高的漏报率. Li等[7]针对缓冲区溢出漏洞提出CLORIFI,利用n-token算法处理输入代码并且使用Bloom filter查找脆弱性代码的克隆,通过concolic测试验证漏洞减少误报. CLORIFI可以提高检测的准确率,但是检测过程中缺少有效的代码归一化方法,无法检测近似克隆,漏报率较高,并且concolic测试方法消耗的资源较多. 甘水滔等[8]提出基于特征矩阵的脆弱代码克隆检测方法CVdetector,遍历漏洞代码片段的语法,分析树构造关键节点的脆弱性特征矩阵与特征向量,利用聚类算法检测多种类型漏洞代码. CVdetector方法的时间开销与检测的代码量呈线性关系,在效率上有较大的提升空间. Li等[9]提出VulPecker、组合Token、AST、PDG等多种中间表示方法,根据代码类型选择对应方法抽取漏洞片段特征,从γ-isomorphic、PCA等相似度比较算法中选取对应的算法,利用支持向量机检测脆弱性代码的复用. VulPecker方法支持多种类型的漏洞,但是计算开销较大,不适用于大规模对象的检测,并且VulPecker对部分代码修改手段不敏感,存在多种误报的情况. Kim等[10]提出高效的函数级脆弱性代码复用检测工具VUDDY,对预处理后的代码进行归一化处理,利用函数的token序列的长度过滤无关代码,使用哈希算法计算函数特征值检测代码克隆. VUDDY具有检测效率高与可扩展性强的优点,但是只能应对简单的代码修改手段,无法检测语序修改、冗余代码插入等常见修改方法,应用场景存在较大的局限.
现有方法为了检测脆弱性代码的近似克隆,通常需要将代码抽象为解析树或控制流图等中间表示,与已知漏洞代码的结构或特征进行匹配. 然而引入复杂的中间表示会带来较高的计算代价,过度抽象可能会导致漏洞必要属性的缺失. 在平衡效率与准确性的前提下,如何有效应对常见的代码修改手段是研究的重点问题.
针对现有方法存在的检测漏报率高、效率低、适用范围小的缺点,提出基于漏洞指纹模型的软件脆弱性代码复用检测方法,设计、实现原型系统SIMVulner. 通过代码相似性定位可能存在漏洞的敏感代码,利用漏洞指纹对代码脆弱性进行判定,实现漏洞代码复用的快速检测. SIMVulner使用基于词频向量的代码过滤与基于LCS的轻量级代码相似性评估算法过滤无关代码、定位敏感代码,提高代码复用的检测效率. 引入基于哈希值的漏洞指纹模型,抽取脆弱性代码细粒度特征,应对代码复用过程中多种常见修改手段带来的影响,提高方法的鲁棒性与实用性.
1 SIMVulner系统设计 1.1 系统框架SIMVulner利用相似性筛选出可能存在脆弱性代码复用的敏感代码,利用漏洞指纹进行识别与定位. SIMVulner系统框架如图1所示,包括漏洞样本库构建、敏感代码定位和基于漏洞指纹的脆弱性代码识别3个部分. 漏洞样本库构建流程如图2所示. 从通用漏洞披露(common vulnerabilities and exposures,CVE)、美国国家漏洞数据库等公开信息库搜集软件漏洞信息,通过关联分析获取漏洞对应软件的信息与相关代码,整合数据构造漏洞样本库作为系统检测的基础. 根据漏洞样本分析引发漏洞的脆弱性代码片段,抽取细粒度特征构造漏洞指纹,结构化存储构建漏洞指纹库用于检测漏洞. 相似性检测模块从漏洞样本中抽取引发漏洞的关键代码片段,使用轻量级代码相似性度量算法评估输入代码与已知漏洞样本关键代码片段的相似度. 将代码中高于阈值的部分标记为敏感代码,筛选出潜在的脆弱性代码克隆. 利用源代码解析器对敏感代码进行相似性最大化处理,根据漏洞指纹库中预构建的漏洞指纹使用指纹识别模块对敏感代码进行脆弱性判定,检测并定位脆弱性代码复用时可能发生的漏洞. SIMVulner利用相似性最大化处理消除代码克隆过程中Level1、2修改的影响,使用合适的粒度提取脆弱性代码特征,支持检测多种漏洞类型;通过相似性检测定位敏感代码,受无关代码的语序调整、冗余插入、等价变换等修改手段的影响较小,有利于提高方法的鲁棒性;引入位图结构判定脆弱性代码克隆,能够提高检测效率.

|
图 1 SIMVulner系统框架 Fig. 1 System framework of SIMVulner |

|
图 2 漏洞样本库构建流程 Fig. 2 Process of constructing vulnerability instance database |
构建漏洞样本库的主要目的是结构化存储软件漏洞信息、漏洞补丁以及相关源代码片段,为基于相似性的敏感代码检测提供支撑. 整合公开信息库中软件漏洞信息组成漏洞样本集合
利用爬虫技术从CVE等网站采集已经公开的开源项目漏洞信息,使用git工具获取对应项目的代码,通过git log命令查询漏洞补丁对应的提交id,参考第三方漏洞信息网站公示的信息验证提交id的准确性. 使用git show命令获取的完整的提交内容中包含对该漏洞的具体描述和统一格式的diff信息. diff信息不仅包含代码补丁中的差异内容,还记录了漏洞修补前后代码版本签名,根据版本签名可以唯一确定代码内容. 根据diff信息准确抓取引发漏洞的关键代码片段,结合漏洞信息进行分类存储作为漏洞样本,构建映射
对Linux Kernel、FFmpeg、ImageMagick、Openssl、Qemu等多个开源项目实施上述步骤,建立包含14个知名开源项目的漏洞样本库,搜集2 634条漏洞信息与1 853条补丁信息及对应的关键代码片段.
1.3 代码相似性评估SIMVulner对输入代码与漏洞样本的关键代码进行相似度评估,检测输入样本中潜在的脆弱性代码复用实例并且标记为敏感代码作为后续检测步骤的输入. 相似性检测流程如图3所示.

|
图 3 SIMVulner检测输入代码与漏洞样本的关键代码相似性的流程 Fig. 3 Process of similarity detection of entered code and critical code of vulnerability instances using SIMVulner |
为了提高检测效率,引入基于词频向量的过滤机制减少方法计算开销. 通过代码格式化将输入代码转换为由代码行片段组成的序列,利用最长公共子序列(longest common subsequence,LCS)算法进行相似度评估,查找漏洞样本的克隆,分类标记、存储结果,构建敏感代码集合.
1.3.1 代码过滤代码过滤的目的是提取出输入样本中可能存在的代码复用的部分,减少无关代码等干扰因素,提高检测效率. 由于漏洞的成因复杂多样,触发的条件与上下文环境密切相关,复用已知脆弱性代码的局部片段不一定会引入相同的漏洞. 为了提高方法的有效性,需要确定被检测的最少代码行数,避免待测代码行数过少引起的假阳性,减少不必要的计算量. 例如检测C语言代码时,根据文献[11],选择连续的6行作为最少检测代码行数筛选输入代码. 为了后续处理更方便,根据实际情况灵活选择合适的最小检测尺寸,例如选择完整的结构体定义、宏定义、函数代码等作为检测对象.
LCS算法处理较长的输入序列时会带来较大的计算量,但是实践中发现大部分代码之间不存在相似性关系. 为了避免不必要的计算,参考现有代码复用检测中的常用手段,引入基于词频向量的过滤机制,利用词频向量预测代码间相似度,提高检测效率. 选择编程语言中部分关键字和运算符组成集合K,通过预处理将代码片段转换为token集合T,计算K中各元素在集合T中出现的频率
相似性检测产生的误报会降低方法效率,漏报会导致检测结果产生假阴性. 有必要通过代码格式化,消除无关因素对检测造成的影响,调整输入代码布局,对代码中部分函数与参数名称进行归一化,提高相似性算法的检测灵敏度. 归一化的方法如下.
1)移除缩进、注释等与代码内容无关的字符,删除大括号、注释,移除缩进、行首行尾的空格.
2)根据指定的代码行拆分规则调整代码格式,将代码转换为由代码行片段组成的序列,有效地反映出代码之间在语句与结构上存在的差异,便于后续使用基于行匹配的相似性检测算法进行评估. 代码行拆分的规则如下.
a)对变量声明与赋值语句进行拆分;
b)对函数定义与函数调用进行拆分;
c)对for、while循环结构进行拆分.
具体的代码行拆分规则如表1所示. SIMVulner根据编程语言词法对代码行进行灵活拆分,检测的最小粒度既可以是单个token,也可以是多个token组成的代码行片段. 灵活可变的拆分规则使得方法可以针对不同的编程语言或特定的代码内容,选择合适的颗粒度,提高检测的准确性.
| 表 1 代码行拆分规则示例 Table 1 Examples of code line splitting |
3)在代码复用过程中,重命名修改会在不影响原有语义的情况下,对基于文本的相似性检测方法造成较大干扰. 对参数名与函数名进行归一化,降低修改变量名、参数名、函数名的重命名修改带来的影响. 归一化手段为在函数定义内,将函数名替换为“func”,变量名替换为“var”,函数参数替换为“param”. 如表2所示为归一化修改的示例.
| 表 2 参数名和函数名的归一化修改示例 Table 2 Examples of normalization of parameter names and function names |
归一化处理后,可得输入代码的代码行片段序列. 中间表示缩小了代码的布局差异,同时突出了语法与结构特征. 如表3所示为不同程度的格式化修改手段对代码匹配结果的影响. 代码格式化在一定程度上屏蔽了不同程度的修改带来的影响,提高了基于文本的相似性检测的准确率.
| 表 3 不同程度的格式化修改手段对代码匹配结果的影响 Table 3 Effect of different formatting modification on code matching results |
SIMVulner中使用LCS算法进行相似度评估. 对于输入文件filei与filej,经过格式化得到代码行片段序列si与sj作为输入,使用LCS算法提取出2个序列间存在的最长公共子序列
| ${\rm{sim}}\,\,({s_i}, {s_j}) = \frac{{\left| {{\rm{LCS\,\,(}}{s_i}, {s_j}{\rm{)}}} \right|}}{{\big| {{s_i}} \big| + \left| {{s_j}} \right| - \left| {{\rm{LCS\,\,(}}{s_i}, {s_j}{\rm{)}}} \right|}}.$ | (1) |
式中:
由上述步骤得到的所有潜在脆弱性代码克隆实例组成敏感代码集合Csens. 使用样本的漏洞编号、漏洞类型与代码位置等信息标记同一漏洞样本对应的敏感代码,以漏洞编号作为索引进行存储,在后续步骤中利用漏洞指纹进行检测.
2 漏洞指纹的提取与识别参考CVE等漏洞数据库中对漏洞信息的表示方法,使用补丁中的diff文件描述漏洞,对比原始代码和修补后的代码刻画漏洞的成因与特点[6, 9-10]. diff文件由1个或多个差异块组成,每个差异块包含若干代码行,每行前面由加号(+)表示增加的代码行,减号(−)表示表示删除的代码行,无符号表示未进行修改[13]. SIMVulner基于已知漏洞的补丁信息构建漏洞指纹,抽取diff文件中差异块的特征作为脆弱代码复用检测的重要依据.
2.1 漏洞指纹设计漏洞指纹的粒度是特征抽取的基本单位,指纹粒度的设计对检测结果有重要影响. 将指纹粒度定为单个代码行不能充分反映代码脆弱性的关键因素与漏洞触发必要的上下文环境,可能会带来较大的误报率. 例如Linux内核中存在的竞争条件漏洞CVE-2015-7550,通过变更security/keys/keyctl.c中的keyctl_read_key函数内语句的顺序完成修正. 如果以单个代码行作为检测粒度,无法表现代码顺序在漏洞成因中的重要影响,适用性较差.
由于可能存在多个必要条件触发漏洞,引发漏洞的关键代码可能分布在多个文件或多个函数中,将指纹粒度限定为单一函数也可能会引起较高的漏报率. 例如在4.5.2版本之前的Linux内核中,网络防火墙子系统存在整型越界漏洞CVE-2016-3134. 补丁中修改了net/ipv4/netfilter/目录下arp_tables.c内arpt_do_table与ip_tables.c内get_entry等多个函数. 仅从单个函数或单个文件中抽取漏洞特征,无法涵盖漏洞触发所需的完整条件,需要选取能够从分散的代码中抽取特征的合适粒度.
SIMVulner选取固定行数的代码块(n-line block, NLB)作为指纹粒度,根据目标代码的编程语言与检测对象的特点确定代码块的行数. 以NLB为基本单位,抽取脆弱性代码与补丁中关键片段,能够有效提取漏洞产生的关键因素,同时保留必要的上、下文环境,满足检测受多种因素共同影响的漏洞的需求. SIMVulner使用的漏洞指纹模型结构如图4所示. 提取漏洞补丁中每个diff文件中的每处修改中的长度适当的代码及上下文,分割成连续的NLB. 使用哈希函数计算所有代码块的特征值,按照增加和删除的分类组成对应的特征序列. 组合漏洞补丁中所有diff文件的特征序列构成完整的漏洞指纹,结构化存储于漏洞指纹库中,用于检测脆弱性代码复用.

|
图 4 漏洞指纹模型结构设计 Fig. 4 Design of vulnerability fingerprint model |
代码解析器作为词法分析与语法分析的组件,是实现代码处理与特征提取步骤的基础. 虽然使用llvm、gcc等编译器集成的解析器可以获取较准确的解析结果,但是其处理大规模代码的效率不高,并且通常无法解析由于代码不完整、语法错误、头文件缺失等原因无法编译的代码. 漏洞样本库内大量脆弱代码样本以无法通过编译的代码片段形式独立存在,编译器中集成的解析器不能解析,需要选择通用性强、稳健性高的解析器.
综合考虑分析性能与准确性,SIMVulner选择基于开源语法分析器ANTLR[14]实现的具有高鲁棒性的C/C++代码解析器,根据预定义的目标编程语言词法规则进行解析,不需要可编译的代码环境或完整的头文件信息. 利用观察者模式遍历目标代码,基于ANTLR的代码解析器可以跳过语法错误或缺失代码片段继续解析[10],具有较好的稳健性与适用性,能够应对复杂多样的代码情景. SIMVulner利用基于ANTLR的代码解析器,抽取目标代码特征序列并且生成代码指纹.
2.2.2 相似性最大化处理为了使代码指纹具有更强的通用性,使用相似性最大化处理消除代码复用过程中修改格式、注释等内容带来的差异,降低重命名修改造成的影响[15]. 将代码全部转换为小写,删除多余空格、换行符以及注释,对代码进行符号替换处理. 考虑编程语言语法制定替换的规则,具体规则如下.
1)函数名与参数名替换. 从函数的声明中获取所有形式参数,使用符号“_PARAM”替换函数体中所有参数变量,使用符号“_FUNCDEC”替换函数声明中的函数名.
2)变量标识符替换. 使用符号“_DATA”替换在函数体内定义并且使用的所有变量.
3)数据类型替换. 使用符号“_TYPE”替换数据类型,包括C语言标准中定义的数据类型与自定义的结构体. 由于结构体在一定程度上反映代码特征,因此保留结构体类型声明关键字struct进行区分. 为了保证解析器性能,不替换结构体内部成员名称;由于变量的类型对整数溢出等类型的漏洞的触发具有重要影响,因此不替换signed、unsigned等类型修饰符.
4)常量替换. 使用符号“_STR”替换代码中字符串常量,但是考虑到可能存在的格式化字符串漏洞,不替换所有print类函数中包含的“%”等格式字符的字符串参数.
5)函数调用替换. 使用符号“_FUNCTION”替换每个被调用的函数的名称. 子函数或应用程序编程接口(application programming interface, API)的调用对漏洞的产生与触发有重要影响,但是出于性能的考虑不具体解析每个调用的具体内容,保留函数调用的参数与用法以描述该调用的特征.
以4.5.5版本之前的Linux内核中存在的拒绝服务漏洞(CVE-2016-6198)为例,漏洞发生在代码fs/open.c中,相关函数的部分代码及处理后结果如下.
/*vfs_open - open the file at the given path*/
int vfs_open(const struct path *path, struct file *file, const struct cred *cred){
struct dentry *dentry = path->dentry;
struct inode *inode = dentry->d_inode;
file->f_path = *path;
if (dentry->d_flags & DCACHE_OP_SELECT_INODE) {
inode = dentry->d_op->d_select_inode (dentry, file->f_flags);
if (IS_ERR(inode))
return PTR_ERR(inode)
}
_TYPE _FUNCDEC(const struct _TYPE *_PARAM, struct _TYPE *_PARAM,
const struct _TYPE *_PARAM){
struct _TYPE *_DATA = _PARAM->dentry;
struct _TYPE *_DATA = dentry->d_inode;
_PARAM->f_path = *_PARAM;
if (_DATA->d_flags & dcache_op_select_inode) {
_DATA=_DATA->d_op->_FUNCTION(_DATA, _PARAM->f_flags);
if (_FUNCTION(_DATA))
return _FUNCTION(_DATA);
}
2.2.3 特征序列抽取代码的特征序列是构成漏洞指纹的基本结构,获取特征序列并生成漏洞指纹的步骤如下.
1)根据漏洞补丁的diff文件确定未修补的原始代码与修补后的代码,选取适当的行数l作为指纹模型中NLB代码块的大小,同时也作为后续检测中使用的滑动窗口尺寸. l对方法的性能有较大影响,偏小会带来较大的计算开销,过大会造成目标代码的特征抽取不够灵活,降低应对代码修改的能力. 根据Jang等[6]的研究可知,检测C语言项目时,l=4.
2)利用NLB提取原始代码中每处被删除的代码记作特征块
3)使用哈希算法计算特征块
4)对补丁所有diff文件进行上述操作,记录对应的特征序列共同组成的漏洞指纹集合
在哈希函数抽取代码块特征值的过程中,哈希算法的选取对检测效率和准确性有重要影响,选取的算法应避免碰撞、简单、高效. 常用的字符串散列算法不适用,CRC32、BKDRHash等高效算法可能会产生大量的哈希冲突引起误报. 综合考虑性能与效率,SIMVulner采用输出为8字节的MD5算法,有利于减少碰撞并且节省存储空间. 例如基于CVE-2016-6198的补丁与相关源代码,通过上述步骤最终可以得到如图5所示的漏洞指纹.

|
图 5 CVE-2016-6198的漏洞指纹结构 Fig. 5 Structure of vulnerability fingerprint for CVE-2016-6198 |
漏洞指纹识别是判定脆弱性代码复用的关键步骤,也是脆弱性代码复用检测的最后一步. 漏洞指纹识别模块计算敏感代码的特征序列,利用位图结构判定敏感代码是否满足指纹模型描述,实现对脆弱性代码复用的识别. 针对敏感代码的特征序列抽取算法如下.
INPUT: Function
Window size sizewin
OUTPUT: Hash value sequence seqf for function f
//Get the total lines of function
line←0
FOR EACH row IN
line←line+1
FOR EACH row' IN
//Get the code block in current window
runk←f[row, row+sizewin]
hash←HASH(trunk)
IF row'+sizewin >line THEN
BREAK
END IF
END FOR
RETURN seqf
算法描述了处理输入的敏感代码的过程,算法的输出为特征值组成的序列
为了提高漏洞指纹识别效率,SIMVulner引入位图结构以简化识别过程. 对于经过相似性评估得到的敏感代码集合Csens,根据标记的漏洞编号等信息选择用于检测的漏洞指纹集合
| $\forall f \in F, \; \exists {b_f} \in {B_F}, \; H\left( f \right) = {b_f}.$ | (2) |
位图
未修补的脆弱性代码复用应该满足判定条件:
| $\exists c \in {C_{{\rm{sens}}}},\;{\text{有}}\;{\rm{Dif}}{{\rm{f}}_{{\rm{sub}}}} \cap c \ne \phi \;{\text{且}}\;{\rm{Dif}}{{\rm{f}}_{{\mathop{\rm add}\nolimits} }} \cap c{\rm{ = }}\phi .$ | (3) |
式中:
| $\forall {\rm{bi}}{{\rm{t}}_{{\rm{add}}}} \in {b_f},\;\forall {\rm{bi}}{{\rm{t}}_{{\rm{del}}}} \in {b_f},\;{\text{有}}\;{\rm{bi}}{{\rm{t}}_{{\rm{add}}}}{\rm{ = }}0\;{\text{并且}}\;{\rm{bi}}{{\rm{t}}_{{\rm{del}}}}{\rm{ = }}1 .$ | (4) |
式(4)限定
| $\begin{array}{l}\forall {\rm{bi}}{{\rm{t}}_a} \in {b_f},\;\forall {\rm{bi}}{{\rm{t}}_b} \in {b_f},\;{\text{若}}\;{\rm{bi}}{{\rm{t}}_a} = 1,\;{\rm{bi}}{{\rm{t}}_b} = 1\;{\text{且}}\\{\rm{Source}}\,\,({\rm{bi}}{{\rm{t}}_a}) = {\rm{Source}}\,\,({\rm{bi}}{{\rm{t}}_b}),\;{\text{则}}\;{\rm{Tag}}\,\,({\rm{bi}}{{\rm{t}}_a}) = {\rm{Tag}}\,\,({\rm{bi}}{{\rm{t}}_b}).\end{array}$ | (5) |
式中:

|
图 6 漏洞指纹位图示例 Fig. 6 Examples for vulnerability fingerprint bitmap |
使用Java语言实现基于漏洞指纹的脆弱性代码复用检测工具SIMVulner,使用开源软件漏洞实例与公开测试集对SIMVulner进行实验与评估.
3.1 测试环境 3.1.1 构建数据库选取知名开源项目如ImageMagick、Linux Kernel、FFmpeg、Openssl、Qemu等作为漏洞样本来源. 根据CVE网站与项目主页的公示信息,选取过去5年中具有代表性的漏洞,搜集漏洞详细信息并且存储对应补丁文件以及相关代码,构建漏洞样本库(vulnerability instance database,VID). 结合第三方漏洞信息网站验证漏洞样本库中信息的准确性,根据漏洞指纹模型设计构建漏洞指纹库(vulnerability fingerprint database,VFD). 由于数据库中部分漏洞补丁信息未公开、漏洞信息无法通过验证,VFD中构造的有效漏洞指纹数量少于VID中样本数量. 实验中选取的开源项目与对应的漏洞数如表4所示.
| 表 4 漏洞样本库与漏洞指纹库数量 Table 4 Number of vulnerability instance databases and vulnerability fingerprint databases |
从漏洞样本库中选取多种具有代表性的漏洞实例,对脆弱性代码进行不同程度的修改,构建包含176个漏洞的脆弱性代码复用集(vulnerability code reuse set, VCRS). 为了检验不同程度的代码修改对检测结果的影响,VCRS中设计5种类型的代码复用实例,分别对应经过Level2、Level3、Level4、Level2+Level3以及Level2+Level4等5种程度修改后的代码. Vulpecker[9]工具开源了用于漏洞代码重用检测研究的漏洞代码实例数据库(vulnerability code instance database, VCID),包含429份经过修改的漏洞代码样本,作为测试集的补充,用于方案的进一步测试与评估.
3.2 结果分析与评价 3.2.1 准确性评估未修补的脆弱性代码与修补后的版本通常具有较高的相似度,使用传统的代码克隆检测工具(如CP-Miner[16]和SourcererCC[17])进行脆弱性代码复用检测时误报率较高. 本研究选择专为脆弱性代码复用检测设计的ReDeBug和VUDDY工具,作为评估SIMVulner有效性的参照.
1)使用SIMVulner检测VCID中429个代码样本,检测到146处脆弱性代码复用,检测精度相比同类工具明显提高,检测结果如表5所示. 某些受多个函数共同影响的漏洞在VCID中对应的实例只包含个别函数的复用代码,不满足漏洞触发的完整条件,不认为是脆弱性代码复用. 在测试阶段,SIMVulner的漏洞样本库不如Vulpecker中使用的漏洞补丁数据库完备,丰富漏洞样本库后能够进一步提高SIMVulner的检测效果.
| 表 5 ReDeBug、VUDDY、SIMVulner对VCID的检测结果对比 Table 5 Comparison of detection results for VCID using ReDeBug, VUDDY and SIMVulner |
2)为了获得不同的方法对不同类型代码修改的检测效果,分别从5种VCRS类型修改实例中各选择20个实例组成准确性评估测试集,涵盖10个知名开源项目与30个真实的CVE漏洞. TP为测试结果中检测到的真实漏洞数,FP为测试结果中的误报数,FN为测试结果中真实漏洞的漏报数. 使用检测精度
| ${\rm{F}}\text{-} {\rm score} = 2{P_{{\rm{acc}}}} {R_{{\rm{recall}}}}/({P_{{\rm{acc}}}} + {R_{{\rm{recall}}}}). $ | (6) |

|
图 7 ReDeBug、VUDDY、SIMVulner对不同类型的脆弱性代码复用检测的结果 Fig. 7 Detection results for different types of vulnerable code reuse using ReDeBug, VUDDY and SIMVulner |
根据实验结果可知,3种工具针对脆弱代码复用过程中常见代码修改手段的检测能力如表6所示. 表中,“√”表示能够应对代码修改手段,“×”表示不能应对代码修改手段,“
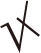 ”表示部分应对代码修改手段.
”表示部分应对代码修改手段.
| 表 6 ReDeBug、VUDDY、SIMVulner对不同代码修改手段的检测效果对比 Table 6 Detection result for different code modification methods using ReDeBug, VUDDY and SIMVulner |
实验在Ubuntu 16.04的服务器上进行,配备Intel Xeon E5 2.40 GHz处理器,64 GB RAM以及6 TB硬盘. 检测VCID时,忽略网络上传时间等无关因素的影响,记录针对不同大小样本检测的时间开销. 如图8所示为SIMVulner与VUDDY检测不同代码行数l所需的时间开销t. VUUDY的检测过程分为2个部分:在本地预处理待检测文件并且生成中间表示;通过网页上传由后台完成检测. 实验表明,VUUDY在预处理阶段的计算开销较大. SIMVulner使用代码过滤与敏感代码定位减少无关代码带来的影响,基于本地漏洞指纹库使用位图结构完成脆弱性代码复用的判定,一次遍历目标代码后完成检测,检测效率较高.

|
图 8 SIMVulner与VUDDY的检测效率对比 Fig. 8 Comparison of efficiency of SIMVulner and VUDDY |
为了评估SIMVulner检测大规模代码时的性能,选取不同大小的10组代码组成测试用例进行效率评估测试. 测试用例选取自Github上Star数量超过100的C语言项目,代码量从

|
图 9 SIMVulner检测所用时间与代码规模的关系 Fig. 9 Relationship between SIMVulner’s detecting time and code scale |
将SIMVulner应用于github上的开源项目,检测到了多个项目中存在的脆弱性代码复用. 在QEMU的源代码中发现了Linux内核漏洞CVE-2009-2768的脆弱代码复用:qemu/linux-user/flatload.c中用于构建bFLT binary loader的函数load_flat_shared_library被认定为是Linux内核历史版本中linux/fs/binfmt_flat.c的复用,函数中存在空指针引用,可能会被拒绝服务攻击. 同时S2E等开源项目也使用了未修补的bFLT binary loader模块代码,存在被拒绝服务攻击的风险. 上述案例表明,在社区活跃的开源项目中,漏洞被披露后能够得到及时修复,但是复用了此类脆弱性代码的第三方项目不一定能够得到同步修复,SIMVulner方法具有良好的实际价值与研究意义.
4 结 语提出了基于漏洞指纹的脆弱性代码复用检测方法,实现了检测脆弱代码复用的系统SIMVulner. 在利用词频向量过滤无关代码的基础上,评估输入样本与已知漏洞代码间相似度,识别可能存在脆弱性代码复用的敏感代码. 引入基于哈希值的漏洞指纹模型对敏感代码进行判定,准确检测脆弱性代码复用. SIMVulner基于词频向量的过滤机制与基于位图的漏洞指纹判定方法,具有较好的效率. 实验结果表明,SIMVulner在一定程度上能够应对Level1至Level4类型的代码修改手段,检测过程的时间开销与输入样本代码量基本呈线性关系. 在实际应用中发现多个开源项目中脆弱性代码复用实例.
后续工作将从以下3个方面开展:进一步简化SIMVulner中使用的哈希函数,减少检测过程的计算量,提高检测效率;丰富和优化漏洞样本库与漏洞指纹数据库以获得更好的性能;将方法与fuzz技术相结合,减少fuzz测试的盲目性,验证脆弱性代码复用是否为可触发漏洞的良好途径.
| [1] |
LOPES C V, MAJ P, MARTINS P, et al. DejaVu: a map of code duplicates on GitHub [J/OL]. Proceedings of the ACM on Programming Languages, 2017, 1(OOPSLA): 84 [2017–11–28]. http://delivery.acm.org/10.1145/3140000/3133908/oopsla17-oopsla176.pdf.
|
| [2] |
BLACK DUCK SOFTWARE. 2017 Open source security and risk analysis report [R/OL]. (2017–4–18)[2017–11–28]. https://www.blackducksoftware.com/open-source-security-risk-analysis-2017.
|
| [3] |
KOROLOV M. Attacks based on open source vulnerabilities will rise 20 percent this year [R/OL]. (2017–1–17)[2017–11–28]. http://www.csoonline.com/article/3157377/application-development/report-attacks-based-on-open-source-vulnerabilities-will-rise-20-percent-this-year.html.
|
| [4] |
JONES E L. Metrics based plagiarism monitoring[J]. Journal of Computing Sciences in Colleges, 2001, 16(4): 253-261. |
| [5] |
ROY C K, CORDY J R, KOSCHKE R, et al. Comparison and evaluation of code clone detection techniques and tools: a qualitative approach[J]. Science of Computer Programming, 2009, 74(7): 470-495. DOI:10.1016/j.scico.2009.02.007 |
| [6] |
JANG J, ABEER A, DAVID B. ReDeBug: finding unpatched code clones in entire OS distributions [C] // IEEE Symposium on Security and Privacy. San Francisco: IEEE, 2012: 48–62. http://www.computer.org/csdl/proceedings/sp/2012/4681/00/06234404-abs.html
|
| [7] |
LI H, KWON H, KWON J, et al. CLORIFI: software vulnerability discovery using code clone verification[J]. Concurrency and Computation Practice and Experience, 2016, 28(6): 1900-1917. DOI:10.1002/cpe.v28.6 |
| [8] |
甘水滔, 秦晓军, 陈左宁, 等. 一种基于特征矩阵的软件脆弱性代码克隆检测方法[J]. 软件学报, 2015, 26(2): 348-363. GAN Shui-tao, QIN Xiao-jun, CHEN Zuo-ning, et al. Software vulnerability code clone detection method based on characteristic metrics[J]. Journal of Software, 2015, 26(2): 348-363. |
| [9] |
LI Z, ZOU D, XU S, et al. VulPecker: an automated vulnerability detection system based on code similarity analysis [C] // Conference on Computer Security Applications. Los Angeles: ACM, 2016: 201–213. http://www.researchgate.net/publication/311491861_VulPecker_an_automated_vulnerability_detection_system_based_on_code_similarity_analysis
|
| [10] |
KIM S, WOO S, LEE H, et al. VUDDY: a scalable approach for vulnerable code clone discovery [C] // Security and Privacy. San Jose: IEEE, 2017: 595–614. https://www.researchgate.net/publication/317919404_VUDDY_A_Scalable_Approach_for_Vulnerable_Code_Clone_Discovery
|
| [11] |
ROY C K, CORDY J R. NICAD: accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization [C] // The 16th IEEE International Conference on Program Comprehension. Amsterdam: IEEE, 2008: 172–181. http://doi.ieeecomputersociety.org/10.1109/ICPC.2008.41
|
| [12] |
KAWAMITSU N, ISHIO T, KANDA T, et al. Identifying source code reuse across repositories using LCS-based source code similarity [C] // International Working Conference on Source Code Analysis and Manipulation. Victoria: IEEE, 2014: 305–314. http://www.researchgate.net/publication/265693213_Identifying_Source_Code_Reuse_across_Repositories_using_LCS-based_Source_Code_Similarity
|
| [13] |
常超, 刘克胜, 赵军, 等. 基于复用代码检测的缺陷发现方法[J]. 系统工程与电子技术, 2017, 9(39): 2157-2164. CHANG Chao, LIU Ke-sheng, ZHAO Jun, et al. Clone flaw detection method based on clone code detection[J]. Systems Engineering and Electronics, 2017, 9(39): 2157-2164. |
| [14] |
PARR T. Another tool for language recognition [EB/OL]. (2013–5–20)[2017–11–28]. http://www.antlr.org/
|
| [15] |
田振洲, 刘烃, 郑庆华, 等. 软件抄袭检测研究综述[J]. 信息安全学报, 2016(3): 52-76. TIAN Zhen-zhou, LIU Ting, ZHENG Qing-hua, et al. Software plagiarism detection: a survey[J]. Journal of Cyber Security, 2016(3): 52-76. |
| [16] |
LI Z, LU S, MYAGMAR S, et al. CP-Miner: finding copy-paste and related bugs in large-scale software code[J]. IEEE Transactions on Software Engineering, 2006, 32(3): 176-192. DOI:10.1109/TSE.2006.28 |
| [17] |
SAJNANI H, SAINI V, SVAJLENKO J, et al. SourcererCC: scaling code clone detection to big-code [C] // 38th International Conference on Software Engineering. Austin: ACM, 2016: 1157–1168. http://www.researchgate.net/publication/287853752_SourcererCC_Scaling_Code_Clone_Detection_to_Big_Code
|