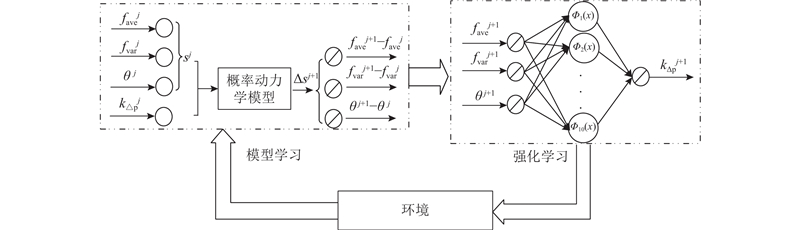
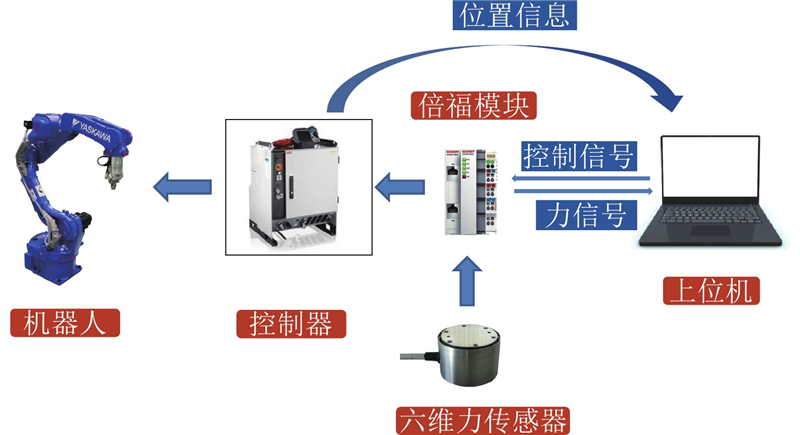
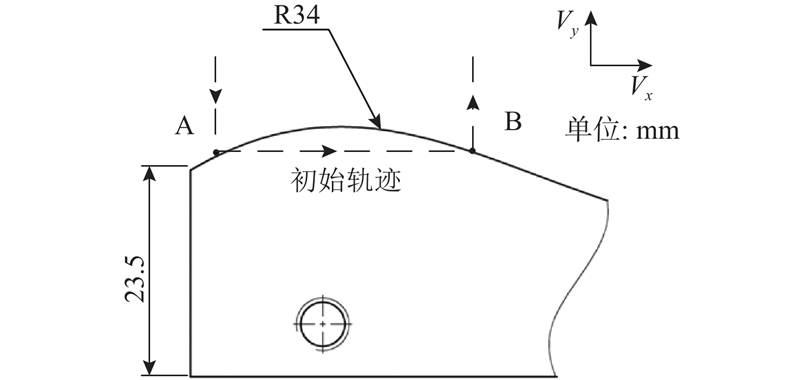
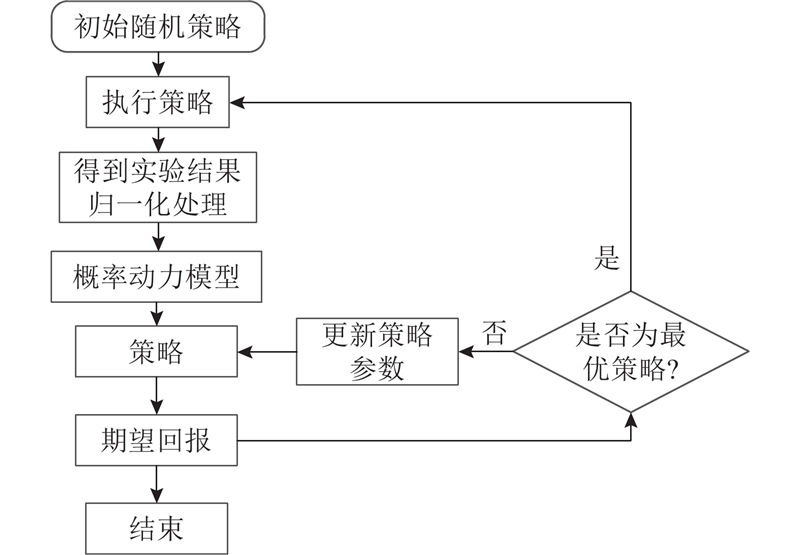
| 机械与能源工程 |
|


|
|
|
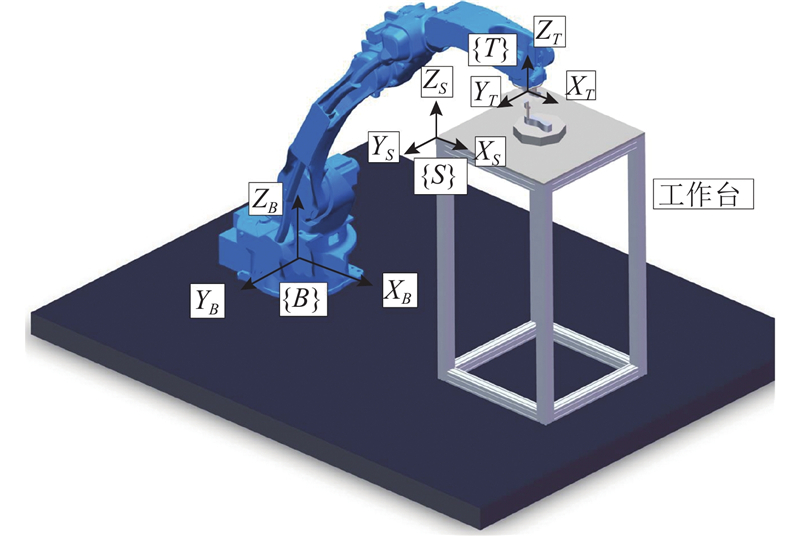
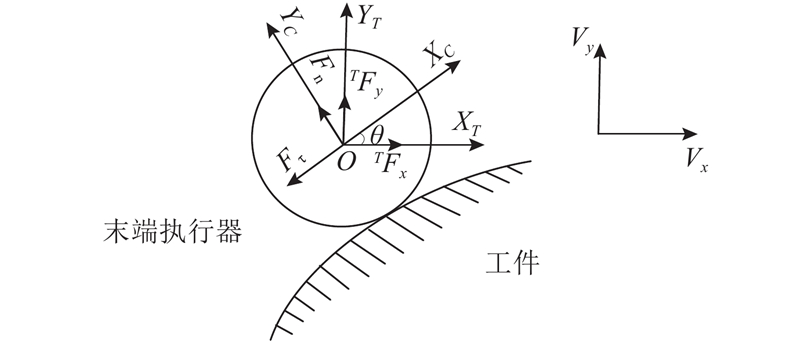
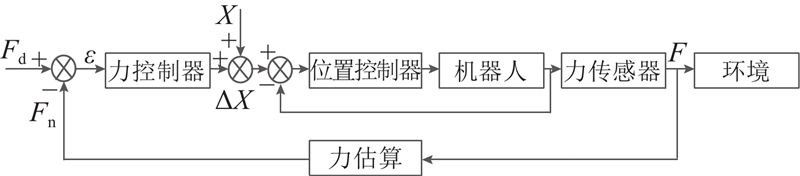
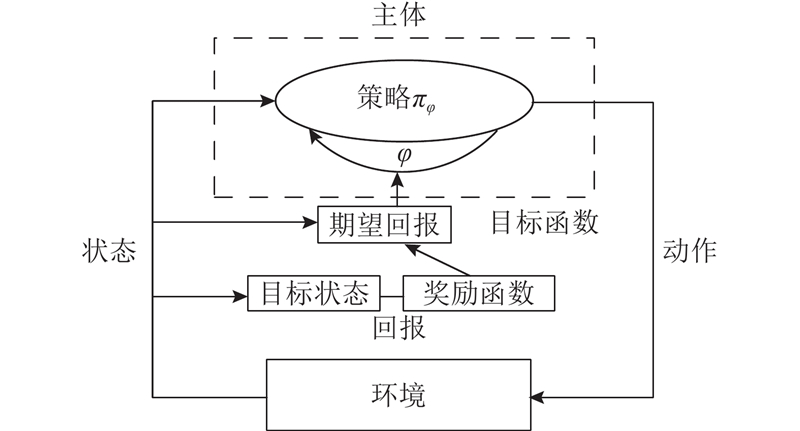
| 基于强化学习的机器人曲面恒力跟踪研究 |
张铁( ),肖蒙,邹焱飚,肖佳栋 ),肖蒙,邹焱飚,肖佳栋 |
| 华南理工大学 机械与汽车工程学院,广东 广州 510640 |
|
| Research on robot constant force control of surface tracking based on reinforcement learning |
| Tie ZHANG(),Meng XIAO,Yan-biao ZOU,Jia-dong XIAO |
| School of Mechanical and Automotive Engineering, South China University of Technology, Guangzhou 510640, China |
引用本文:
张铁,肖蒙,邹焱飚,肖佳栋. 基于强化学习的机器人曲面恒力跟踪研究[J]. 浙江大学学报(工学版), 2019, 53(10): 1865-1873.
Tie ZHANG,Meng XIAO,Yan-biao ZOU,Jia-dong XIAO. Research on robot constant force control of surface tracking based on reinforcement learning. Journal of ZheJiang University (Engineering Science), 2019, 53(10): 1865-1873.
链接本文:
http://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2019.10.003
或
http://www.zjujournals.com/eng/CN/Y2019/V53/I10/1865
|
| 1 |
ALICI G, SHIRINZADEH B Enhanced stiffness modeling, identification and characterization for robot manipulators[J]. IEEE Transactions on Robotics, 2005, 21 (4): 554- 564
doi: 10.1109/TRO.2004.842347
|
| 2 |
黄奇伟, 章明, 曲巍崴, 等 机器人制孔姿态优化与光顺[J]. 浙江大学学报: 工学版, 2015, 49 (12): 2261- 2268
HUANG Qi-wei, ZHANG Ming, QU Wei-wei, et al Posture optimization and smoothness for robot drilling[J]. Journal of Zhejiang University: Engineering Science, 2015, 49 (12): 2261- 2268
|
| 3 |
WINKLER A, SUCHY J. Force controlled contour following on unknown objects with an industrial robot [C]//IEEE International Symposium on Robotic and Sensors Environments (ROSE). Washington, DC: IEEE, 2013: 208-213.
|
| 4 |
TUNG P, FAN S Application of fuzzy on-line self-adaptive controller for a contour tracking robot on unknown contours[J]. Fuzzy Sets and Systems, 1996, 82 (1): 17- 25
doi: 10.1016/0165-0114(95)00272-3
|
| 5 |
ABU-MALLOUH M, SURGENOR B. Force/velocity control of a pneumatic gantry robot for contour tracking with neural network compensation [C]// ASME 2008 International Manufacturing Science and Engineering Conference. Evanston, Illinois, USA: ASME, 2008: 11-18.
|
| 6 |
LI E C, LI Z M Surface tracking with robot force control in unknown environment[J]. Advanced Materials Research, 2011, 328-330: 2140- 2143
doi: 10.4028/www.scientific.net/AMR.328-330
|
| 7 |
YE B S, SONG B, LI Z Y, et al A study of force and position tracking control for robot contact with an arbitrarily inclined plane[J]. International Journal of Advanced Robotic Systems, 2013, 10 (1): 1- 1
doi: 10.5772/52938
|
| 8 |
DUAN J J, GAN Y H, CHEN M, et al Adaptive variable impedance control for dynamic contact force tracking in uncertain environment[J]. Robotics and Autonomous Systems, 2018, 102: 54- 65
doi: 10.1016/j.robot.2018.01.009
|
| 9 |
NUCHKRUA T, CHEN S L Precision contouring control of five degree of freedom robot manipulators with uncertainty[J]. International Journal of Advanced Robotic Systems, 2017, 14 (1): 208- 213
|
| 10 |
WANG W C, LEE C H. Fuzzy neural network-based adaptive impedance force control design of robot manipulator under unknown environment [C]//IEEE International Conference on Fuzzy Systems. Beijing: IEEE, 2014: 1442-1448.
|
| 11 |
KOBER J, BAGNELL J A, PETERS J Reinforcement learning in robotics: a survey[J]. The International Journal of Robotics Research, 2013, 32 (11): 1238- 1274
doi: 10.1177/0278364913495721
|
| 12 |
NG A Y. Shaping and policy search in reinforcement learning [D]. California: University of California, Berkeley, 2003.
|
| 13 |
MüLLING K, KOBER J, KROEMER O, et al Learning to select and generalize striking movements in robot table tennis[J]. The International Journal of Robotics Research, 2013, 32 (3): 263- 279
doi: 10.1177/0278364912472380
|
| 14 |
HESTER T, QUINLAN M, STONE P. Generalized model learning for Reinforcement Learning on a humanoid robot [C]// IEEE International Conference on Robotics and Automation. Anchorage: IEEE, 2010: 2369-2374.
|
| 15 |
YEN G G, HICKEY T W Reinforcement learning algorithms for robotic navigation in dynamic environments[J]. ISA Transactions, 2004, 43 (2): 217- 230
doi: 10.1016/S0019-0578(07)60032-9
|
| 16 |
ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38
doi: 10.1109/MSP.2017.2743240
|
| 17 |
POLYDOROS A S, NALPANTIDIS L Survey of model-based reinforcement learning: applications on robotics[J]. Journal of Intelligent and Robotic Systems, 2017, 86 (2): 1- 21
|
| 18 |
DOERR A, TUONG N D, MARCO A, et al. Model-based policy search for automatic tuning of multivariate PID controllers [C]//2017 IEEE International Conference on Robotics and Automation (ICRA). Singapore: IEEE, 2017: 5295-5301.
|
| 19 |
HAN H, GAUL P, MATSUBARA T. Model-based reinforcement learning approach for deformable linear object manipulation [C]//2017 13th IEEE Conference on Automation Science and Engineering (CASE). Xi'an: IEEE, 2017: 750-755.
|
| 20 |
ZENG G, HEMAMI A An overview of robot force control[J]. Robotica, 1997, 15 (5): 473- 482
doi: 10.1017/S026357479700057X
|
| 21 |
SHENG X, XU L, WANG Z A position-based explicit force control strategy based on online trajectory prediction[J]. International Journal of Robotics and Automation, 2017, 32 (1): 93- 100
|
| 22 |
VOLPE R, KHOSLA P A theoretical and experimental investigation of explicit force control strategies for manipulators[J]. IEEE Transactions on Automatic Control, 1993, 38 (11): 1634- 1650
doi: 10.1109/9.262033
|
| 23 |
KOMATI B, PAC M R, RANATUNGA I, et al. Explicit force control vs impedance control for micromanipulation [C]//ASME 2013 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference. Portland: ASME, 2013: V001T09A018.
|
| 24 |
DEISENROTH M P, RASMUSSEN C E. PILCO: a model-based and data-efficient approach to policy search [C]// International Conference on International Conference on Machine Learning. Bellevue: Omnipress, 2011: 465-472.
|
| 25 |
DEISENROTH M P. Efficient reinforcement learning using Gaussian processes [M]. Karlsruhe, Germany: KIT, 2010.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|